《learn to count everything》论文阅读
本文最后更新于 2024年10月21日 早上
《learn to count everything》论文阅读
模式识别这门课最后选了这篇论文汇报,记录一下吧。
参考资料:
【论文解读】CVPR2021 | FamNet:密集场景计数统计实战 Learning To Count Everything(图像处理|计算机视觉|人工智能)_哔哩哔哩_bilibili
CVPR 2021 | FamNet | Learning To Count Everything - 知乎 (zhihu.com)

本篇论文完成了小样本新类别密集计数任务,给出少量的样本标签即可,是一种半监督的任务。Few-Shot:只给出少量的标签,让模型自己学习,让模型的通用性更强。在本文中,few-shot实现的是:输入为一张图像以及一些标注信息,这些标注信息是少量的目标物体样例,使用方框标注。输出是一张“密度图”,预测和原图同位置的地方是否有目标。最后对密度图做一个求和操作。
1.本文创新点:
- 将计数看成是few-shot回归任务。
- 构建了一种新的网络结构FamNet 少样本适应和匹配性网络。
- 在测试时采用了一种新的自适应方案,进一步提高了FamNet的性能。
- 提供了一个新的数据集Few-Shot Counting-147(FSC-147)。

2.主要结构
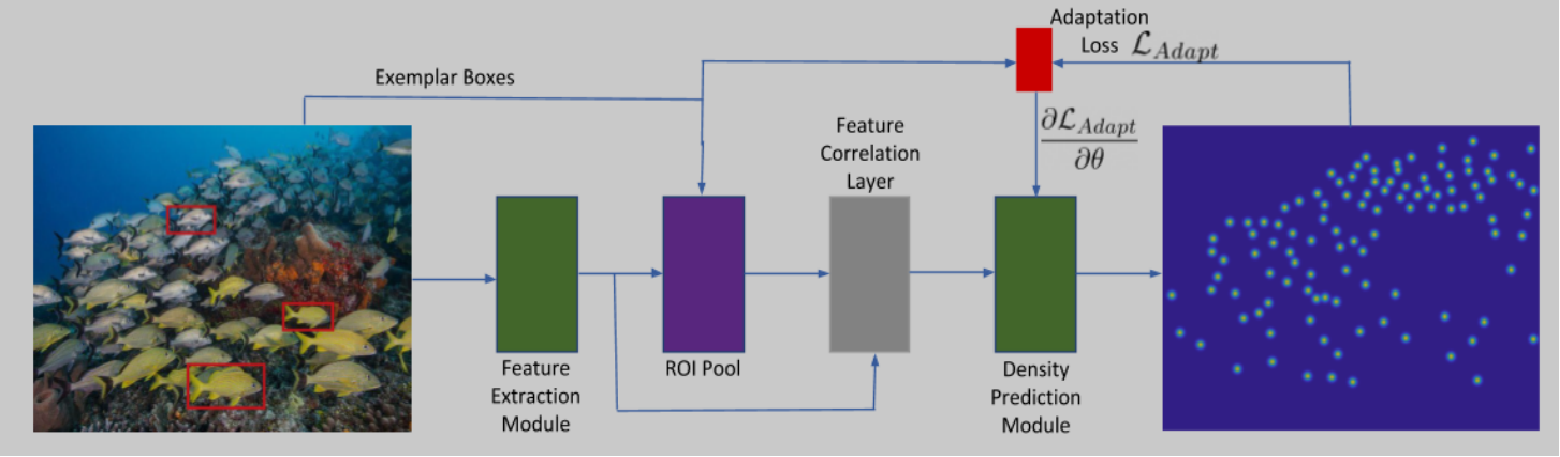
- Feature Extraction Module:特征提取模块。使用ImageNet预训练的网络进行特征提取。多由预先训练好的ResNet-50骨干网的前四个块组成(这些块的参数在训练期间被冻结),通过第三和第四块的卷积特征图来表示一幅图像。
- ROI Pool :只针对关注区域的特征找到特征图。把样例的特征图做上采样或者下采样,然后进行拼接。
- Feature Correlation Layer:特征相关层。为了使密度预测模块对视觉类别不可知,不直接使用从特征提取模块获得的特征进行密度预测。只使用不同scale的样例特征和整个图像特征之间的相关性获得相关图,作为密度预测模块的输入。
- Density Prediction Module:密度预测模块。由五个卷积块和放置在第一、第二和第三卷积层之后的三个上采样层组成。最后一层是 1×1 卷积层预测 2D 密度图。
3.训练(训练集下载见github地址,不大)
FSC-147。由6135张图像组成,涉及147个对象类别。数据集中的对象的大小和计数差异很大,7-3731个对象,平均每幅图像的计数为56个对象。

为了生成目标密度图,使用具有自适应窗口大小的高斯平滑法。首先,使用点注释来估计物体的大小。点注释图每个点都位于物体的近似中心,计算每个点与其最近的邻居的距离,对图像中所有的点进行平均,平均距离被用作生成目标密度图的高斯窗口的大小。高斯的标准偏差被设定为窗口大小的四分之一。为了训练FamNet,将预测的密度图和GT密度图之间的平均平方误差降到最低。使用Adam优化器,学习率为1e-5,批次大小为1。每张图片的大小调整为固定的384高度,宽度也相应调整保持原始纵横比。
4.测试适应
参数微调:在测试时要先“热身,使网络更适应于当前的目标类别,要做某一个类别,先做100次迭代,更新参数。同时,在测试时选择了两个在训练的时候没有的损失函数。其关键思想是利用范例边界框的位置所提供的信息。
第一个是Min-count Loss,要求在密度图的原图样例位置,方框内密度值求和至少大于等于1,否则损失就很大。
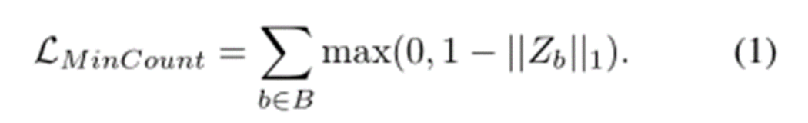
第二个是Perturbation Loss,将方框的中心视作密度值为1,周围的密度值呈高斯分布,离中心位置越远密度值越小。损失函数定义为预测值与中心点的距离(或者说预测密度值与所在位置的实际密度值之差)的平方和。
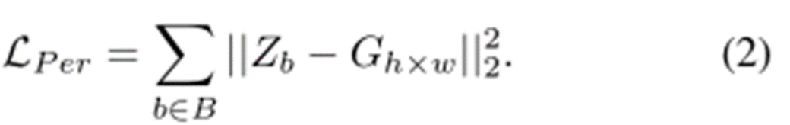
The combined adaptation Loss.用于测试时间自适应的损失是MinCount损失和扰动损失的加权组合。
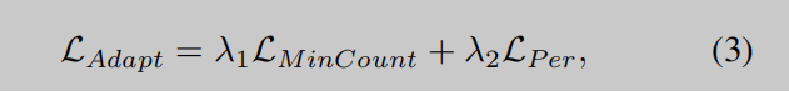
5.有无自适应的测试效果
1.预测的密度图和FamNet的计数。
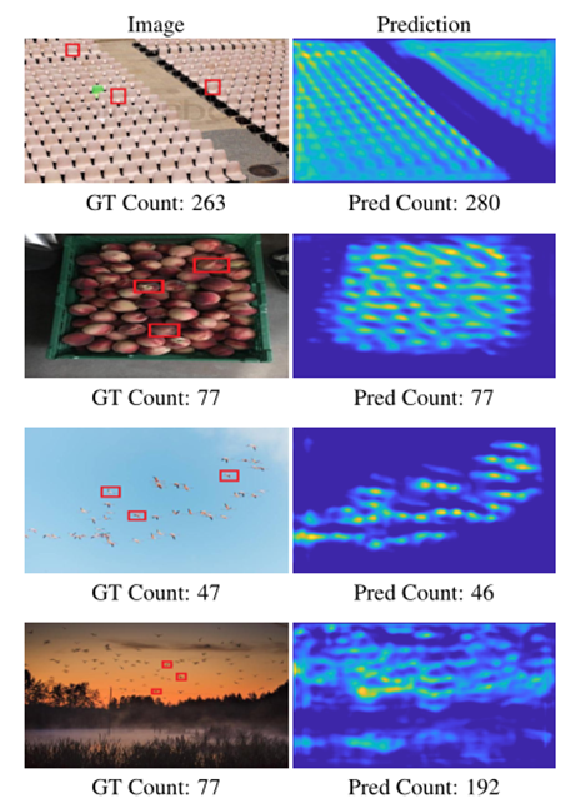
2.测试时自适应。显示的是初始密度图(Pre Adapt)和适应后的最终密度图(Post Adapt)。在过度计数的情况下,适应性降低了密集位置的密度值。

6.实验结果
度量标准:均值绝对误差MAE、均方误差RMSE
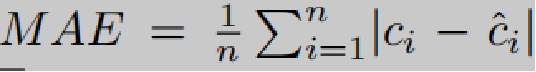
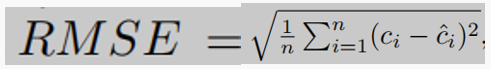
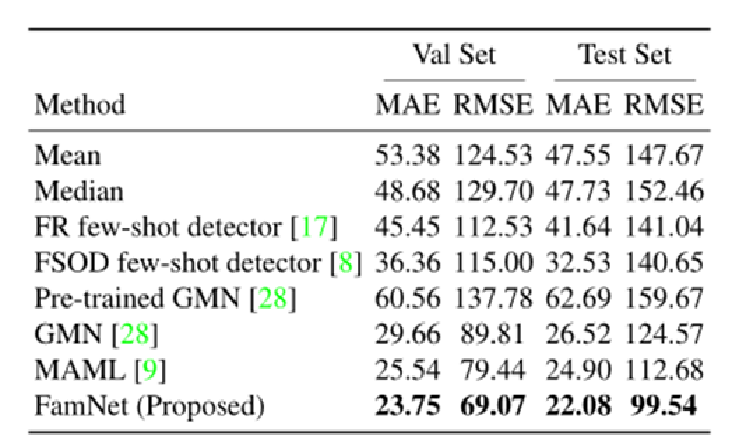
1.与其他少样本方法的比较
2.相比于目标检测的方法
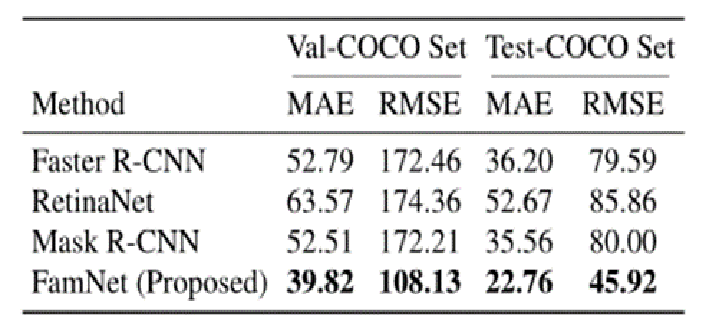
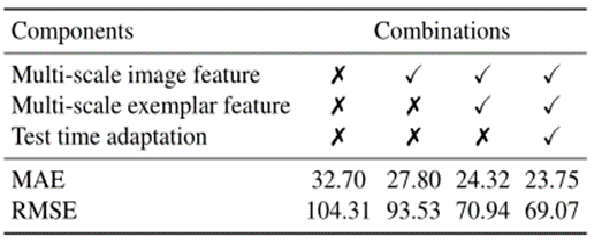
3.消融实验

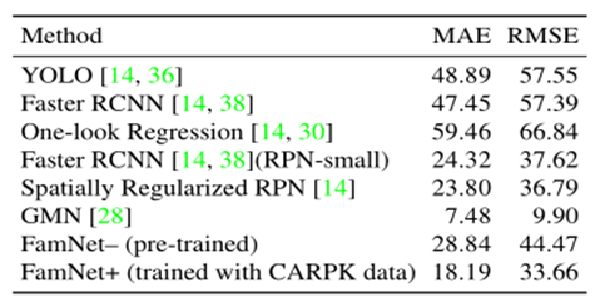
4.特定类别的目标计数
实验过程及结果
1.demo测试:
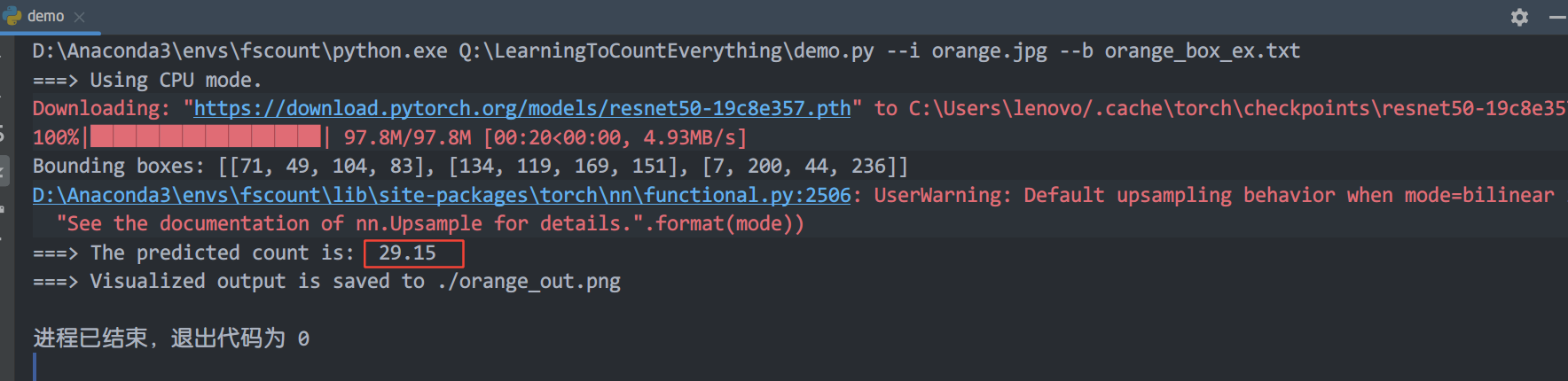
原图应该共有36个橘子,无适应测试结果是29.15,有适应的结果是30.05,略有改善。

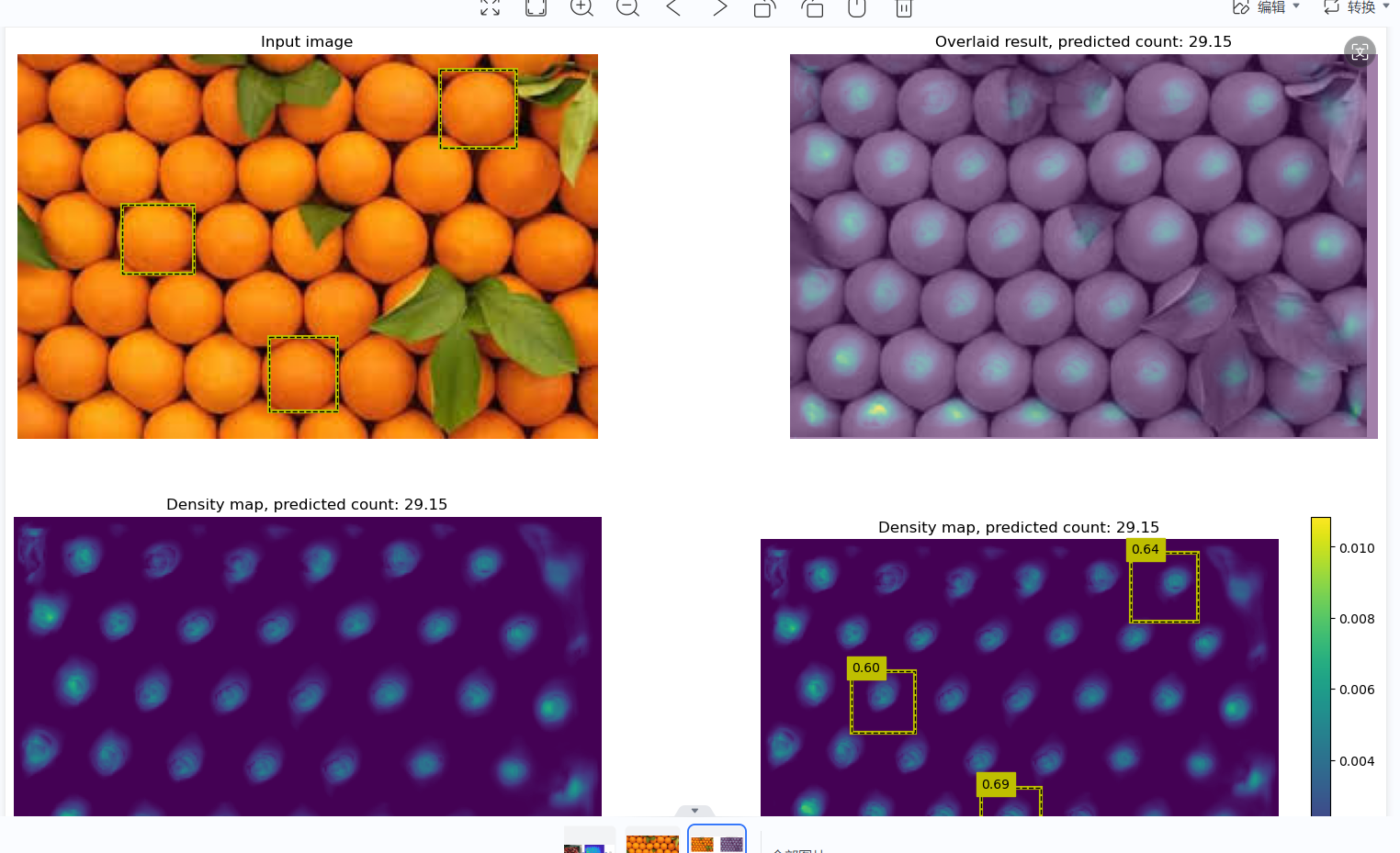

换example box再测试:
特地挑了几个有树叶阻挡的橘子作为example box,结果有所改观。
无适应的结果32.83.

有适应的结果33.86.

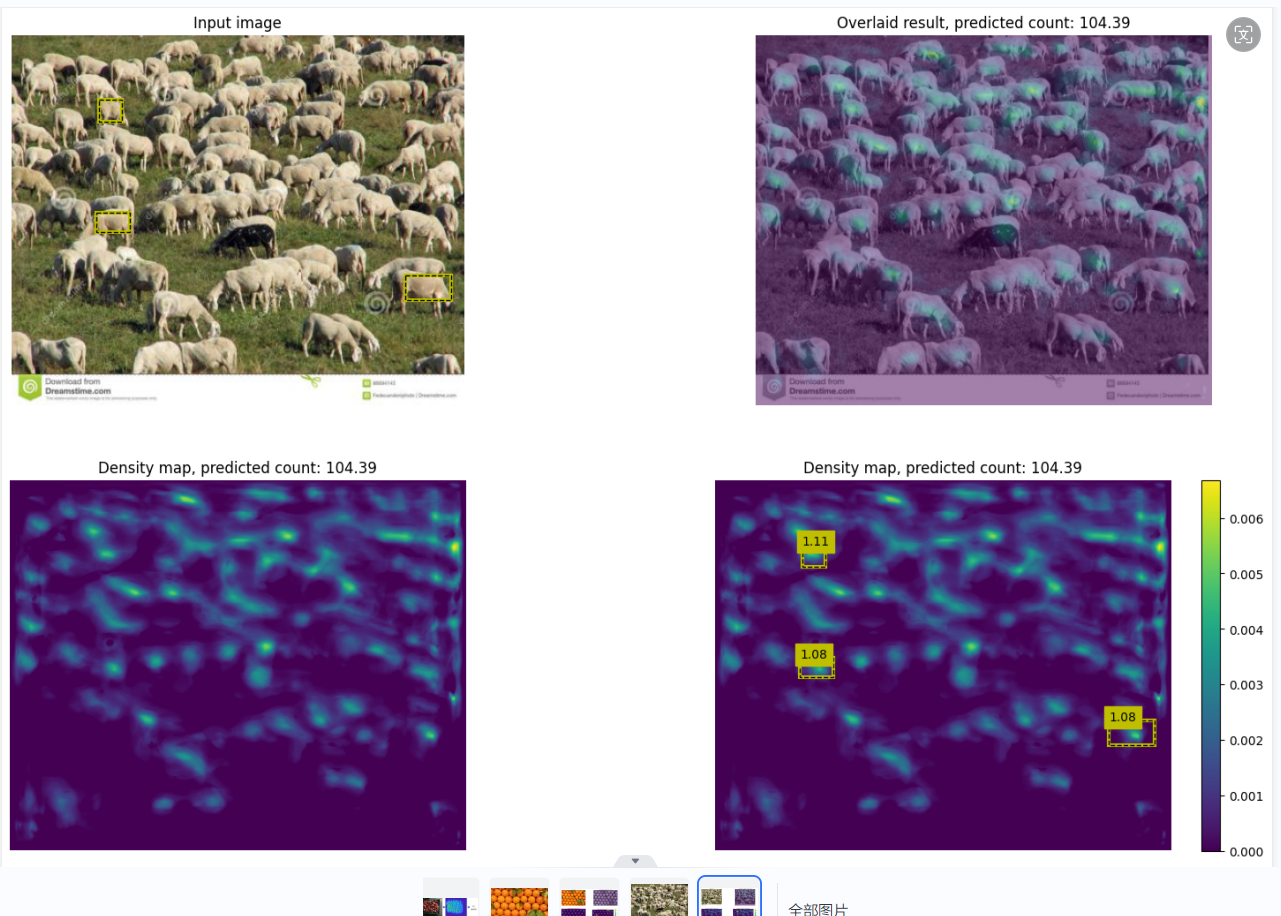
换了一张更密集的羊群图片来测试,误差会更明显。
原图:羊的数量为110左右。


无适应47.16 -> 有适应104.39
在不适应的情况下对测试集进行test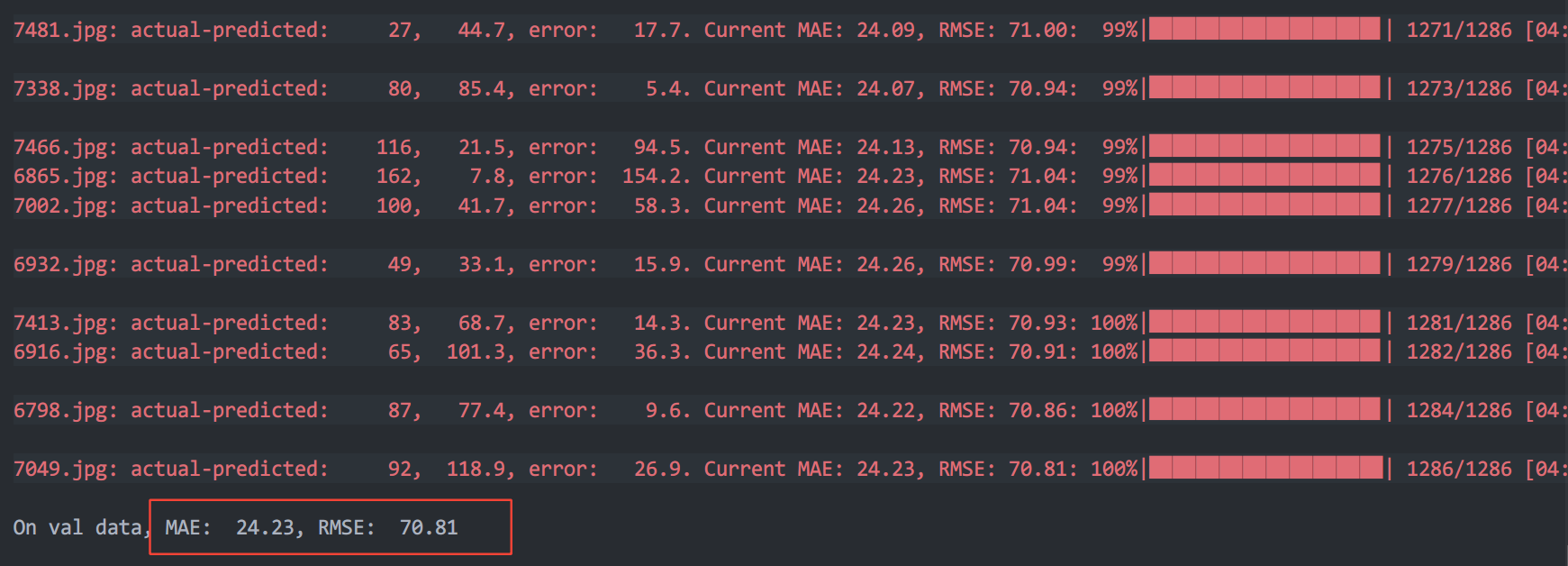
适应的情况下对 val 拆分进行test
官方模型的test
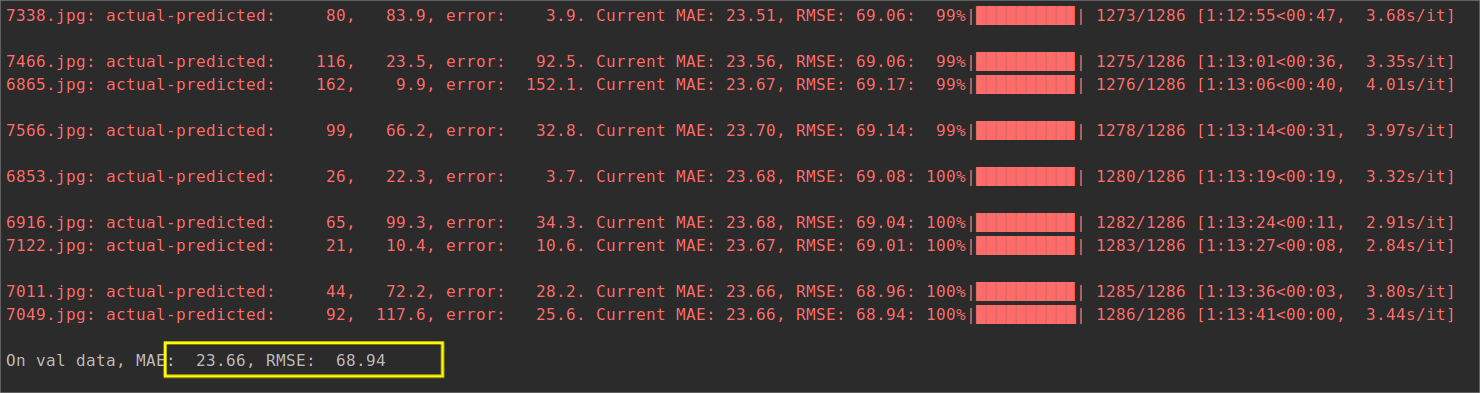
我自己训练的152轮得到model,然后进行test

可以看到结果还是差一点。
起初运行train.py的没看清epoch的default为1500,然后跑了12小时发现才150+轮,算了算实验室的四核GPU得跑五天五夜不止,于是就没跑完,效果还是次了一点。