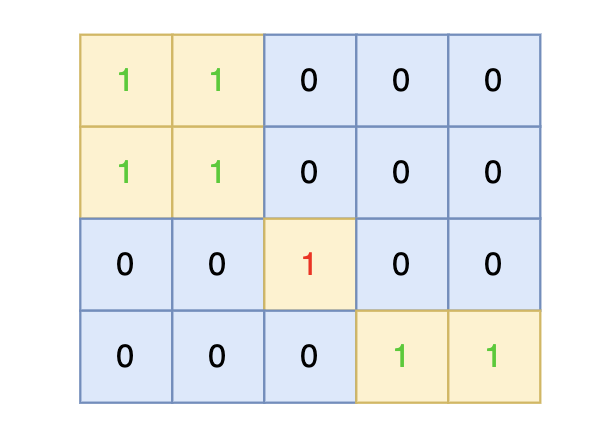
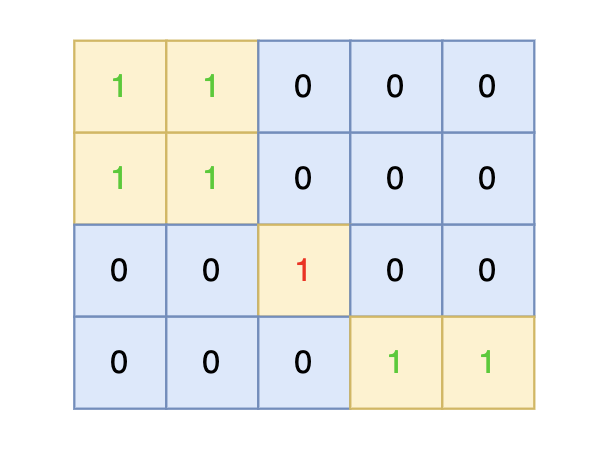
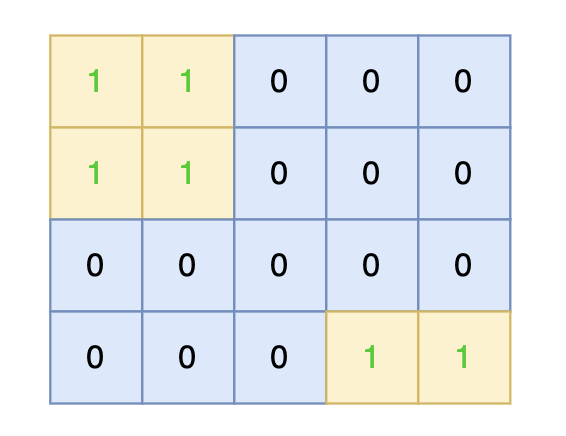
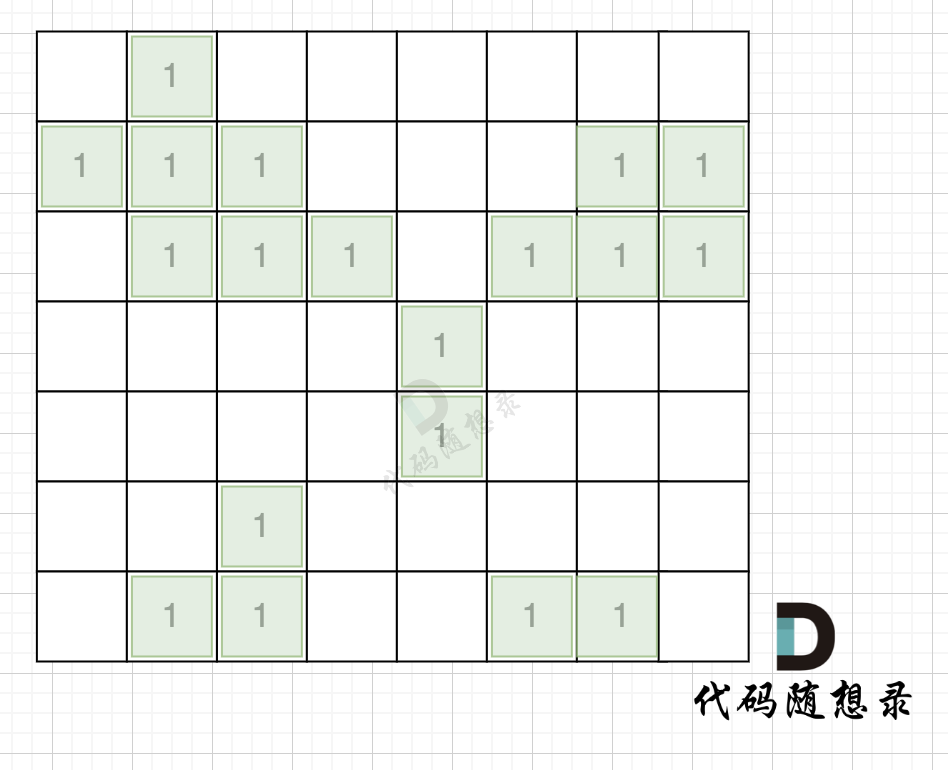
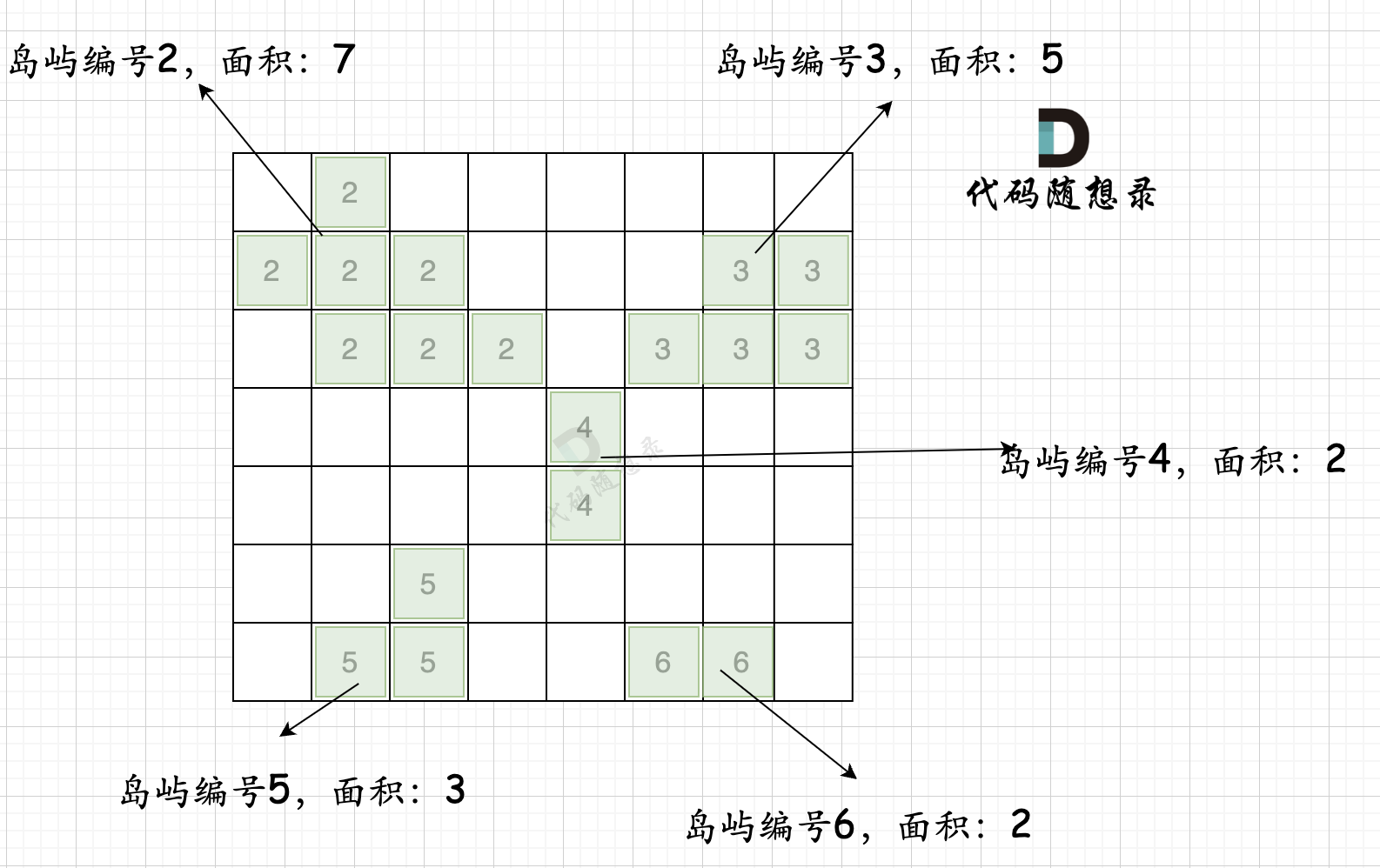
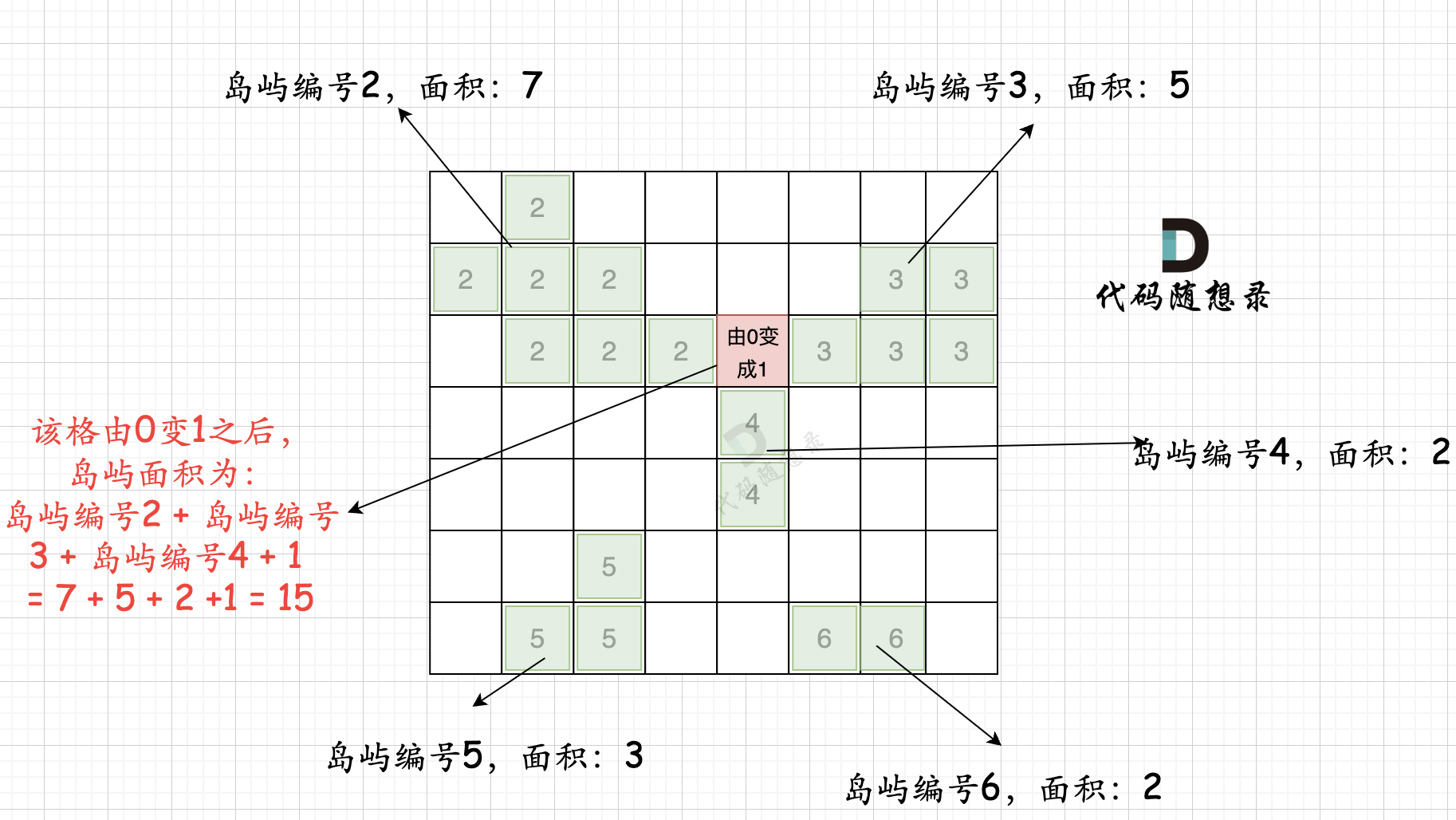
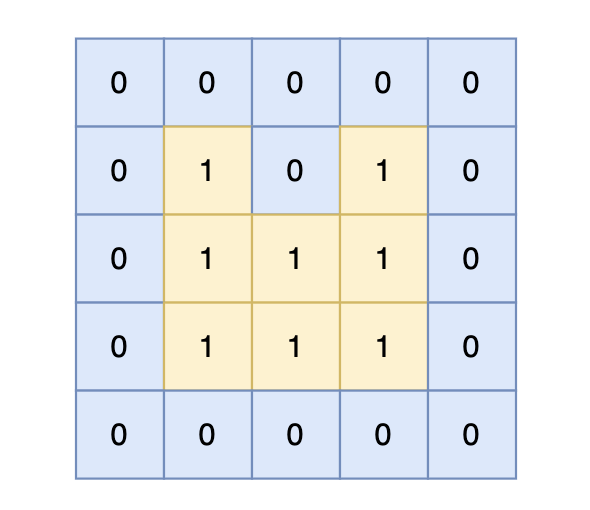
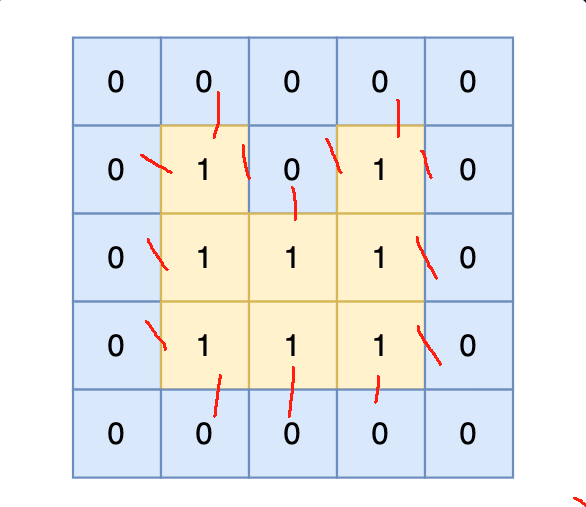
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } }
// 版本二 #include<iostream> #include<vector> usingnamespace std; int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向 voiddfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){ if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水 visited[x][y] = true; // 标记访问过 for (int i = 0; i < 4; i++) { int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过 dfs(grid, visited, nextx, nexty); } }
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } }
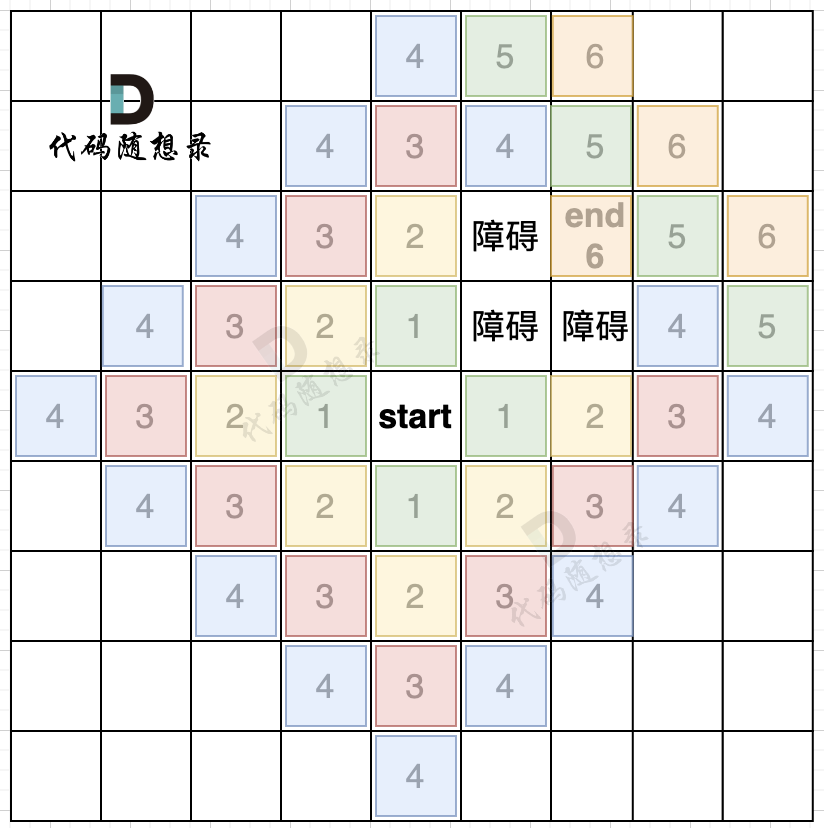
int result = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (!visited[i][j] && grid[i][j] == 1) { result++; // 遇到没访问过的陆地,+1 dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true } } } cout << result << endl; }
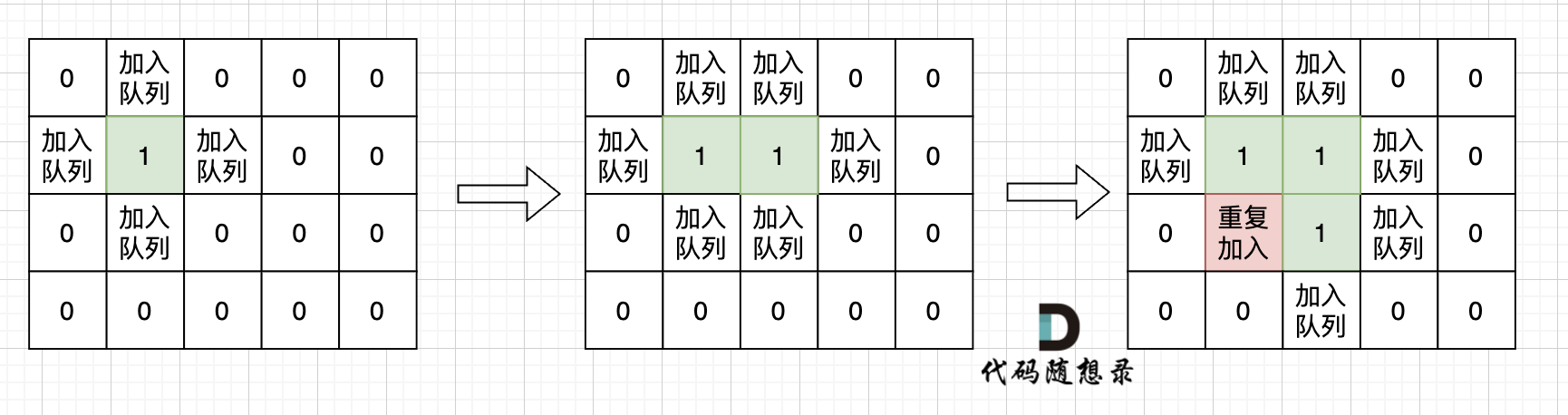
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向 voidbfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){ queue<pair<int, int>> que; que.push({x, y}); visited[x][y] = true; // 只要加入队列,立刻标记 while(!que.empty()) { pair<int ,int> cur = que.front(); que.pop(); int curx = cur.first; int cury = cur.second; for (int i = 0; i < 4; i++) { int nextx = curx + dir[i][0]; int nexty = cury + dir[i][1]; if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过 if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) { que.push({nextx, nexty}); visited[nextx][nexty] = true; // 只要加入队列立刻标记 } } } }
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } }
int result = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (!visited[i][j] && grid[i][j] == 1) { result++; // 遇到没访问过的陆地,+1 bfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true } } }
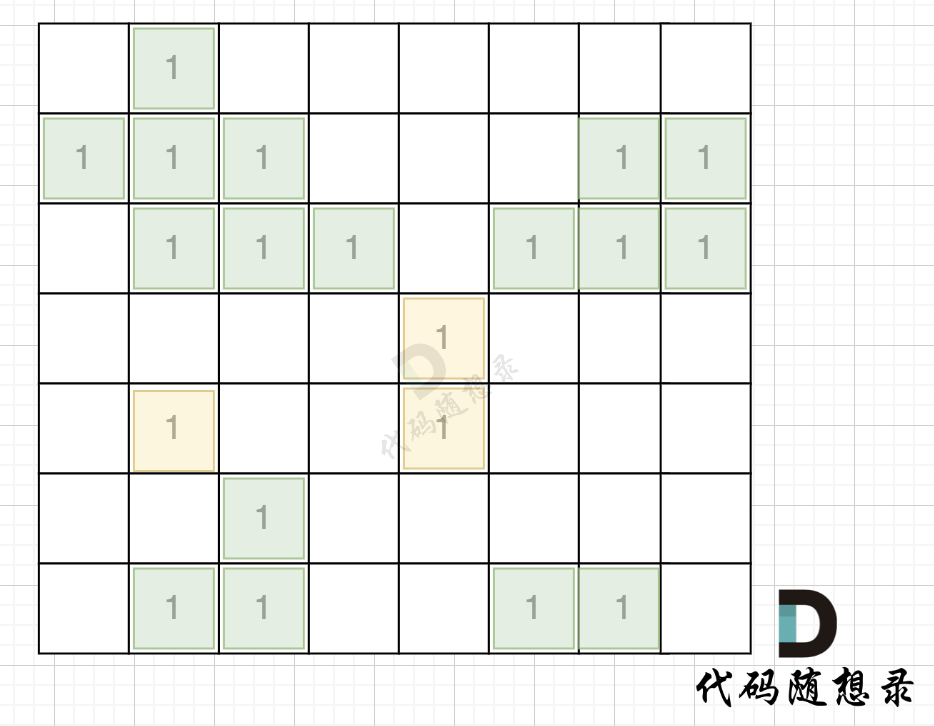
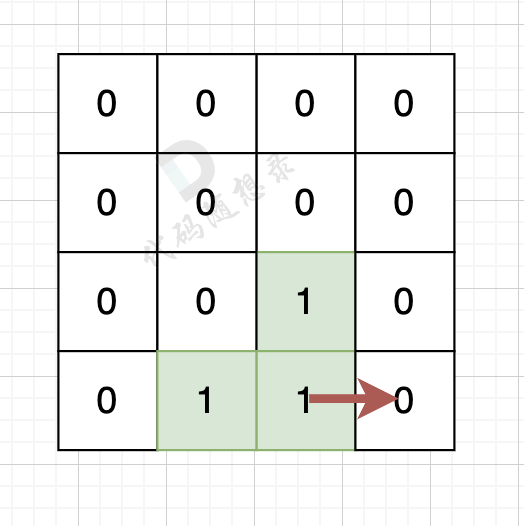
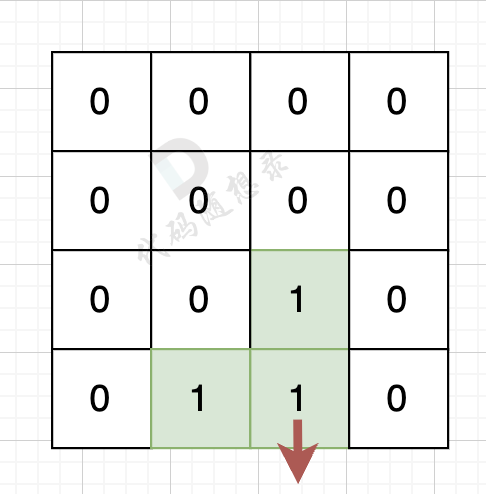
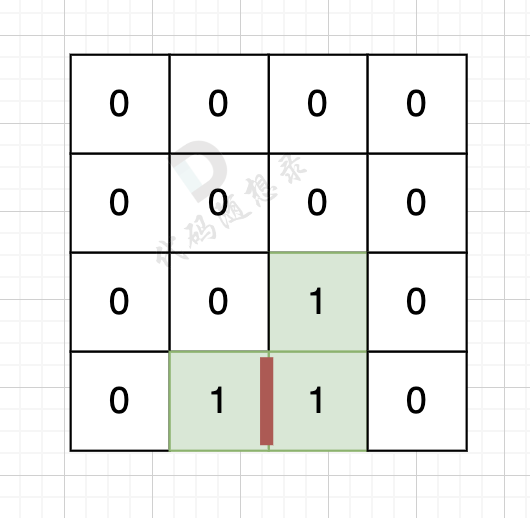
// 版本一 #include<iostream> #include<vector> usingnamespace std; int count; int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向 voiddfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){ for (int i = 0; i < 4; i++) { int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过 if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) { // 没有访问过的 同时 是陆地的 visited[nextx][nexty] = true; count++; dfs(grid, visited, nextx, nexty); } } }
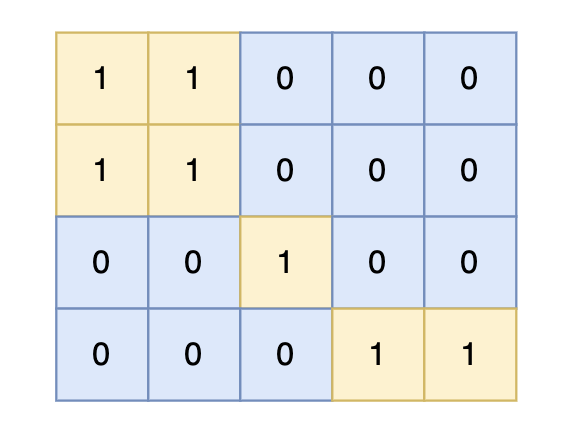
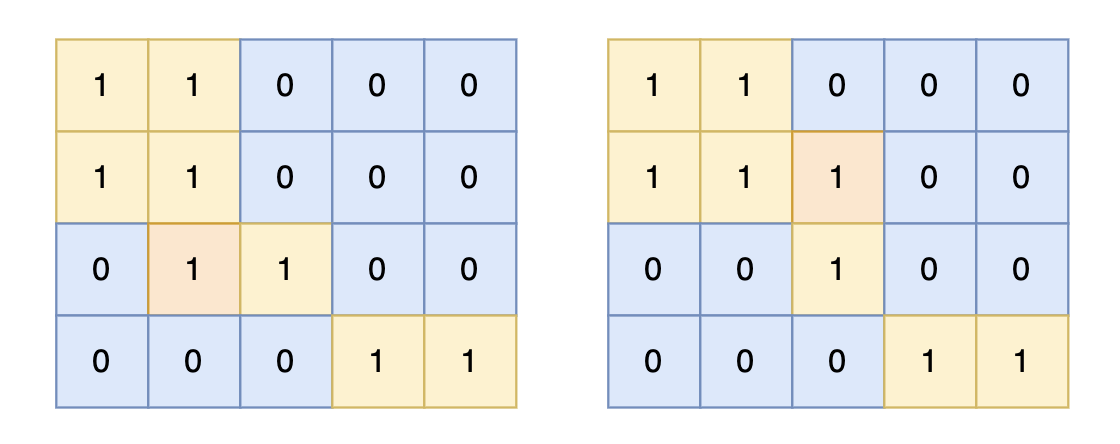
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } } vector<vector<bool>> visited(n, vector<bool>(m, false)); int result = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (!visited[i][j] && grid[i][j] == 1) { count = 1; // 因为dfs处理下一个节点,所以这里遇到陆地了就先计数,dfs处理接下来的相邻陆地 visited[i][j] = true; dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true result = max(result, count); } } } cout << result << endl;
voidbfs(const vector<vector<int>>& grid , vector<vector<bool>>& visited , int x , int y){ queue<pair<int , int>> que; que.push({x , y}); visited[x][y] = true;// 加入队列就意味节点是陆地可到达的点 cnt ++; while(!que.empty()){ pair<int , int> cur = que.front(); que.pop(); int curx = cur.first; int cury = cur.second; for (int i = 0; i < 4; i++) { int nextx = curx + dir[i][0]; int nexty = cury + dir[i][1]; if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;//越界判定 // 节点没有被访问过且是陆地 if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){ visited[nextx][nexty] = true; cnt ++; que.push({nextx , nexty}); } } } }
intmain(){ int n , m ; cin >> n >> m; vector<vector<int>> grid(n , vector<int>(m , 0)); for (int i = 0; i < n; i++) { for(int j = 0 ; j < m ; j++){ cin >> grid[i][j]; } }
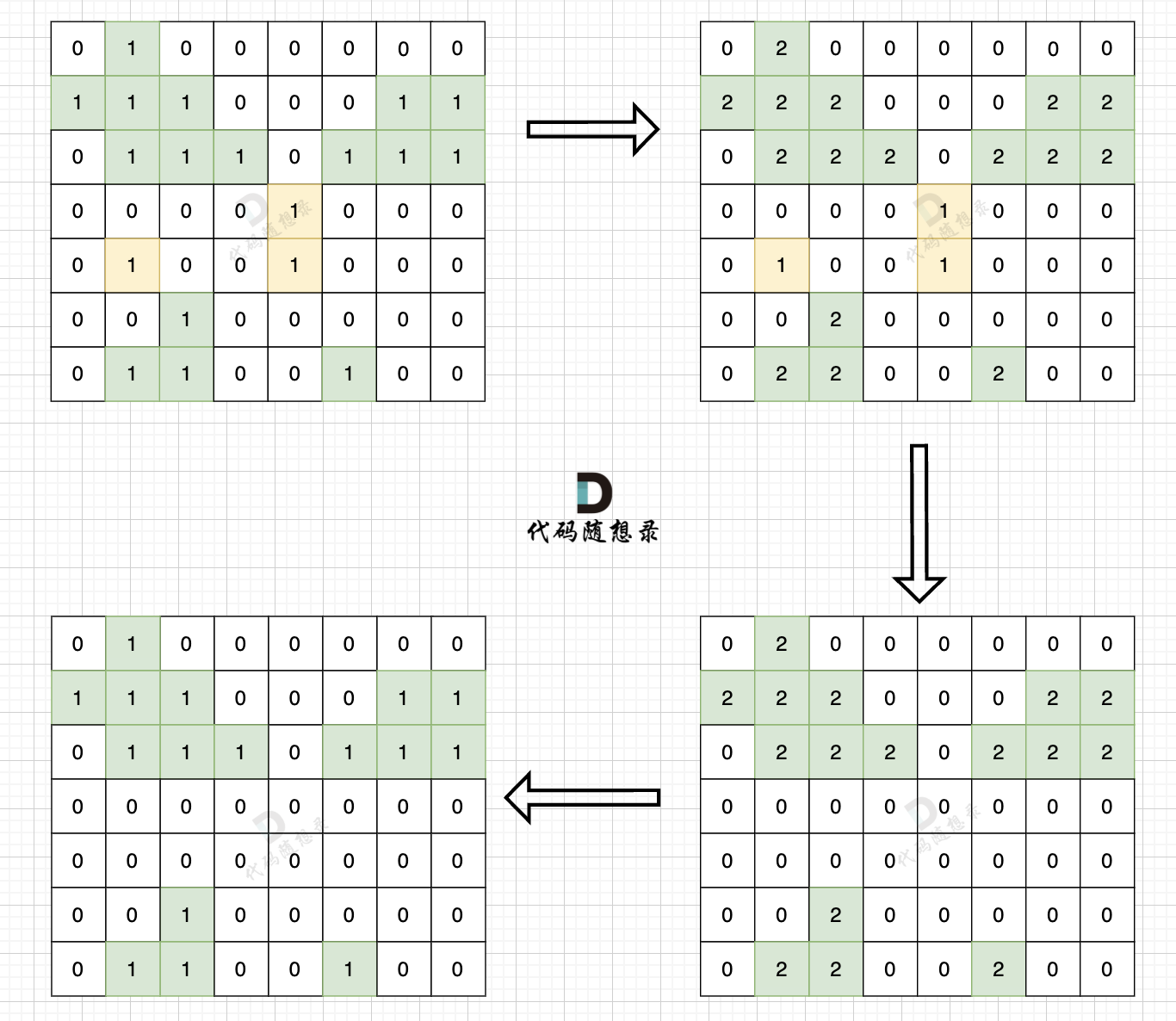
#include<iostream> #include<vector> usingnamespace std; int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向 int count; // 统计符合题目要求的陆地空格数量 voiddfs(vector<vector<int>>& grid, int x, int y){ grid[x][y] = 0; count++; for (int i = 0; i < 4; i++) { // 向四个方向遍历 int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; // 超过边界 if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 不符合条件,不继续遍历 if (grid[nextx][nexty] == 0) continue;
dfs (grid, nextx, nexty); } return; }
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } }
// 从左侧边,和右侧边 向中间遍历 for (int i = 0; i < n; i++) { if (grid[i][0] == 1) dfs(grid, i, 0); if (grid[i][m - 1] == 1) dfs(grid, i, m - 1); } // 从上边和下边 向中间遍历 for (int j = 0; j < m; j++) { if (grid[0][j] == 1) dfs(grid, 0, j); if (grid[n - 1][j] == 1) dfs(grid, n - 1, j); } count = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (grid[i][j] == 1) dfs(grid, i, j); } } cout << count << endl; }
int count = 0; int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
voidbfs(vector<vector<int>>& grid, int x, int y){ queue<pair<int, int>> que; que.push({x, y}); grid[x][y] = 0; // 只要加入队列,立刻标记 count++; while(!que.empty()) { pair<int ,int> cur = que.front(); que.pop(); int curx = cur.first; int cury = cur.second; for (int i = 0; i < 4; i++) { int nextx = curx + dir[i][0]; int nexty = cury + dir[i][1]; if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过 if (grid[nextx][nexty] == 1) { que.push({nextx, nexty}); count++; grid[nextx][nexty] = 0; // 只要加入队列立刻标记 } } } }
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } } // 从左侧边,和右侧边 向中间遍历 for (int i = 0; i < n; i++) { if (grid[i][0] == 1) bfs(grid, i, 0); if (grid[i][m - 1] == 1) bfs(grid, i, m - 1); } // 从上边和下边 向中间遍历 for (int j = 0; j < m; j++) { if (grid[0][j] == 1) bfs(grid, 0, j); if (grid[n - 1][j] == 1) bfs(grid, n - 1, j); } count = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (grid[i][j] == 1) bfs(grid, i, j); } }
#include<iostream> #include<vector> usingnamespace std; int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向 voiddfs(vector<vector<int>>& grid, int x, int y){ grid[x][y] = 2; for (int i = 0; i < 4; i++) { // 向四个方向遍历 int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; // 超过边界 if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 不符合条件,不继续遍历 if (grid[nextx][nexty] == 0 || grid[nextx][nexty] == 2) continue; dfs (grid, nextx, nexty); } return; }
intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } }
// 步骤一: // 从左侧边,和右侧边 向中间遍历 for (int i = 0; i < n; i++) { if (grid[i][0] == 1) dfs(grid, i, 0); if (grid[i][m - 1] == 1) dfs(grid, i, m - 1); }
// 从上边和下边 向中间遍历 for (int j = 0; j < m; j++) { if (grid[0][j] == 1) dfs(grid, 0, j); if (grid[n - 1][j] == 1) dfs(grid, n - 1, j); } // 步骤二、步骤三 for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (grid[i][j] == 1) grid[i][j] = 0; if (grid[i][j] == 2) grid[i][j] = 1; } } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cout << grid[i][j] << " "; } cout << endl; } }
#include<iostream> #include<vector> usingnamespace std; int n, m; int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
// 从 x,y 出发 把可以走的地方都标记上 voiddfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){ if (visited[x][y]) return;
visited[x][y] = true;
for (int i = 0; i < 4; i++) { int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue; if (grid[x][y] < grid[nextx][nexty]) continue; // 高度不合适
dfs (grid, visited, nextx, nexty); } return; } boolisResult(vector<vector<int>>& grid, int x, int y){ vector<vector<bool>> visited(n, vector<bool>(m, false));
#include<iostream> #include<vector> usingnamespace std; int n, m; int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; voiddfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){ if (visited[x][y]) return;
visited[x][y] = true;
for (int i = 0; i < 4; i++) { int nextx = x + dir[i][0]; int nexty = y + dir[i][1]; if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue; if (grid[x][y] > grid[nextx][nexty]) continue; // 注意:这里是从低向高遍历
dfs (grid, visited, nextx, nexty); } return; }
intmain(){
cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0));
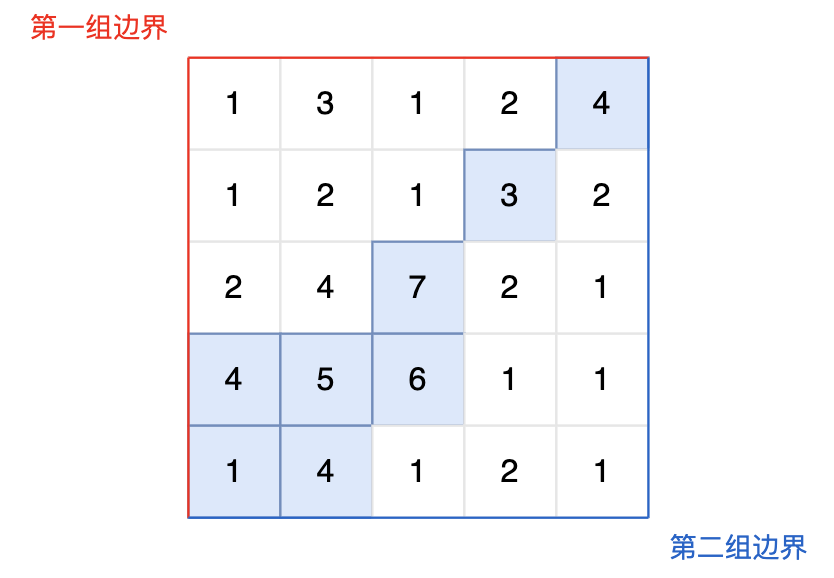
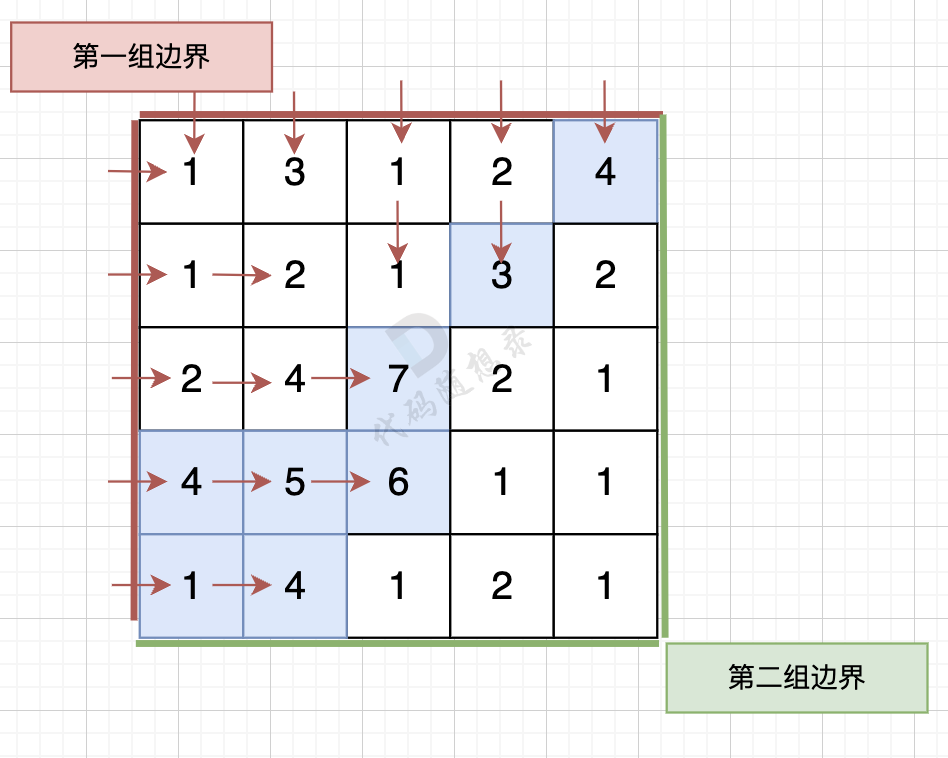
for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } } // 标记从第一组边界上的节点出发,可以遍历的节点 vector<vector<bool>> firstBorder(n, vector<bool>(m, false));
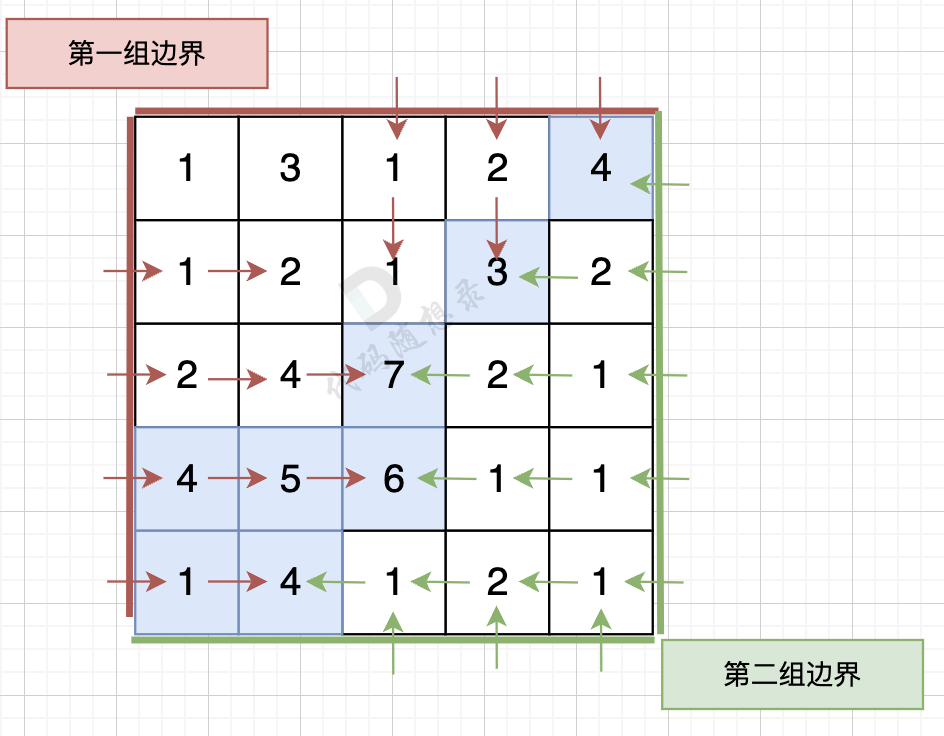
// 从最上和最下行的节点出发,向高处遍历 for (int i = 0; i < n; i++) { dfs (grid, firstBorder, i, 0); // 遍历最左列,接触第一组边界 dfs (grid, secondBorder, i, m - 1); // 遍历最右列,接触第二组边界 }
// 从最左和最右列的节点出发,向高处遍历 for (int j = 0; j < m; j++) { dfs (grid, firstBorder, 0, j); // 遍历最上行,接触第一组边界 dfs (grid, secondBorder, n - 1, j); // 遍历最下行,接触第二组边界 } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { // 如果这个节点,从第一组边界和第二组边界出发都遍历过,就是结果 if (firstBorder[i][j] && secondBorder[i][j]) cout << i << " " << j << endl;; } } }
所以,以下这段代码的时间复杂度是 $2 n m$。 地图用每个节点就遍历了两次,参数传入 firstBorder 的时候遍历一次,参数传入 secondBorder 的时候遍历一次。
1 2 3 4 5 6 7 8 9 10 11
// 从最上和最下行的节点出发,向高处遍历 for (int i = 0; i < n; i++) { dfs (grid, firstBorder, i, 0); // 遍历最左列,接触第一组边界 dfs (grid, secondBorder, i, m - 1); // 遍历最右列,接触第二组边界 }
// 从最左和最右列的节点出发,向高处遍历 for (int j = 0; j < m; j++) { dfs (grid, firstBorder, 0, j); // 遍历最上行,接触第一组边界 dfs (grid, secondBorder, n - 1, j); // 遍历最下行,接触第二组边界 }
那么本题整体的时间复杂度其实是:$ 2 n m + n m $,所以最终时间复杂度为 $O(n m)$ 。
#include<iostream> #include<vector> usingnamespace std; intmain(){ int n, m; cin >> n >> m; vector<vector<int>> grid(n, vector<int>(m, 0)); for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> grid[i][j]; } } int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; int result = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (grid[i][j] == 1) { for (int k = 0; k < 4; k++) { // 上下左右四个方向 int x = i + direction[k][0]; int y = j + direction[k][1]; // 计算周边坐标x,y if (x < 0// x在边界上 || x >= grid.size() // x在边界上 || y < 0// y在边界上 || y >= grid[0].size() // y在边界上 || grid[x][y] == 0) { // x,y位置是水域 result++; } } } } } cout << result << endl;