6.7-哈希表
本文最后更新于 2024年10月21日 早上
哈希表
哈希表(英文名字为Hash table,国内也有一些算法书籍翻译为散列表,大家看到这两个名称知道都是指hash table就可以了)。
哈希表是根据关键码的值而直接进行访问的数据结构。
数组就是一张哈希表。哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素。
那么哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是==O(n)==,但如果使用哈希表的话, 只需要==O(1)==就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
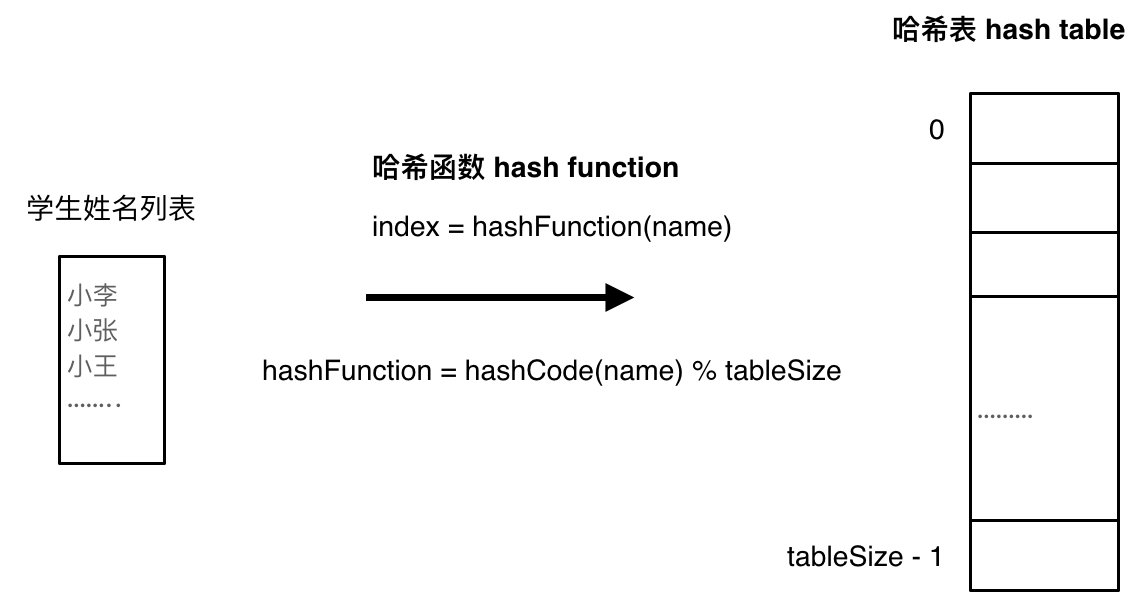
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
哈希碰撞
一般哈希碰撞有两种解决方法,拉链法和线性探测法。
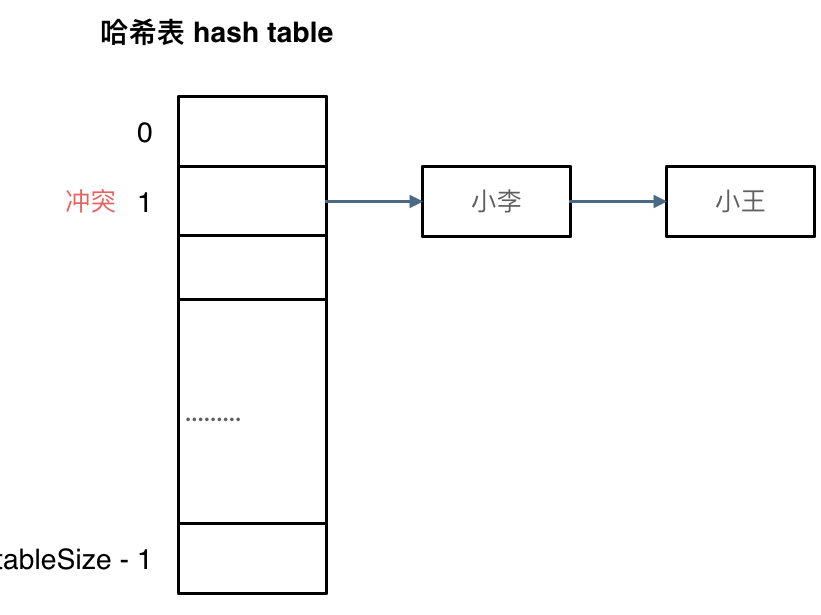
拉链法:
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了。
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
图中数据规模是==dataSize==, 哈希表的大小为==tableSize==。
线性探测法
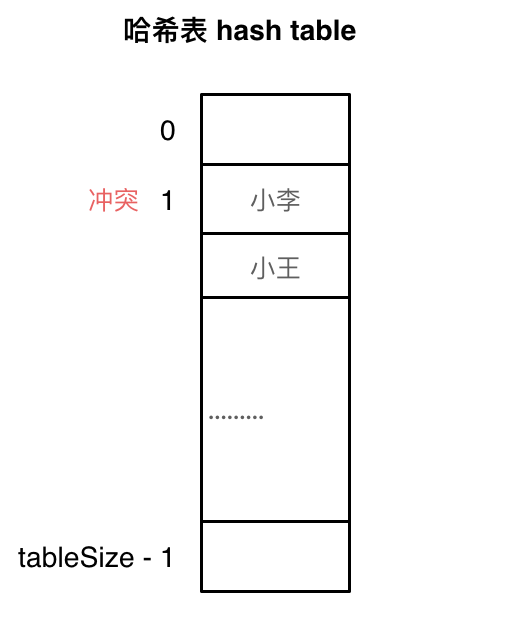
使用线性探测法,一定要保证==tableSize==大于==dataSize==。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求==tableSize==一定要大于==dataSize== ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:
常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
这里数组就没啥可说的了,我们来看一下set。
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
==std::unordered_set==底层实现为哈希表,==std::set== 和==std::multiset== 的底层实现是红黑树,红黑树是一种==平衡二叉搜索树==,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以==只能删除和增加==。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
==std::unordered_map== 底层实现为哈希表,==std::map== 和==std::multimap== 的底层实现是红黑树。同理,==std::map== 和==std::multimap== 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
当我们要使用集合来解决哈希问题的时候,优先使用==unordered_set==,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map ,map 是一个==key value== 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
其他语言例如:java里的==HashMap== ,==TreeMap== 都是一样的原理。可以灵活贯通。
虽然==std::set、std::multiset== 的底层实现是红黑树,不是哈希表,==std::set、std::multiset== 使用红黑树来索引和存储,不过给我们的使用方式,还是哈希法的使用方式,即==key==和==value==。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。 map也是一样的道理。
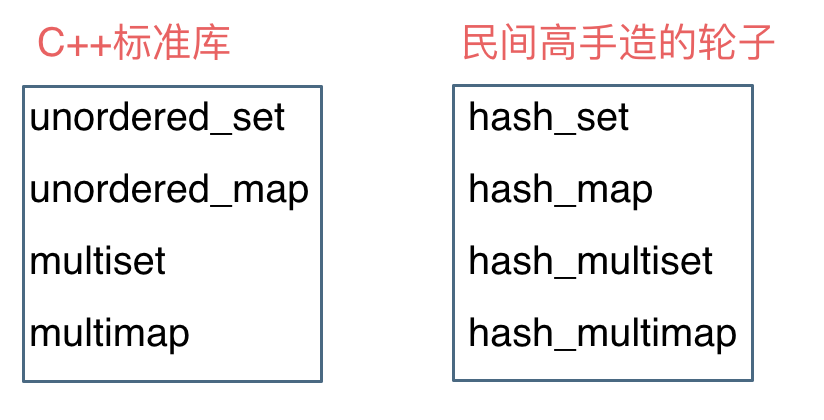
这里在说一下,一些C++的经典书籍上 例如STL源码剖析,说到了==hash_set、 hash_map==,这个与==unordered_set,unordered_map==又有什么关系呢?
实际上功能都是一样一样的, 但是==unordered_set==在C++11的时候被引入标准库了,而==hash_set==并没有,所以建议还是使用==unordered_set==比较好,这就好比一个是官方认证的,==hash_set,hash_map== 是C++11标准之前民间高手自发造的轮子。
总结
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
242. 有效的字母异位词
题意描述:
给定两个字符串
s和t,编写一个函数来判断t是否是s的字母异位词。注意:若
s和t中每个字符出现的次数都相同,则称s和t互为字母异位词。示例 1:
2输入: s = "anagram", t = "nagaram"
输出: true示例 2:
2输入: s = "rat", t = "car"
输出: false提示:
1 <= s.length, t.length <= 5 * 104s和t仅包含小写字母进阶: 如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
思路:
数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符(这点很重要),那么就可以定义一个数组,来记录字符串s里字符出现的次数。
需要定义一个多大的数组呢,定一个数组叫做==record==,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
为了方便举例,判断一下字符串s= “aee”, t = “eae”。
操作动画如下:
定义一个数组叫做==record==用来上记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
在遍历字符串s的时候,只需要将
s[i] - ‘a’所在的元素做+1操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。

AC代码:
1 | |
时间复杂度: O(n)
空间复杂度: O(1)
383. 赎金信
题意描述:
给你两个字符串:
ransomNote和magazine,判断ransomNote能不能由magazine里面的字符构成。如果可以,返回
true;否则返回false。
magazine中的每个字符只能在ransomNote中使用一次。示例 1:
2输入:ransomNote = "a", magazine = "b"
输出:false示例 2:
2输入:ransomNote = "aa", magazine = "ab"
输出:false示例 3:
2输入:ransomNote = "aa", magazine = "aab"
输出:true提示:
1 <= ransomNote.length, magazine.length <= 105ransomNote和magazine由小写英文字母组成
思路:
同上一道,改成==有元素大于0则return false==(表示magazine覆盖不了ransomNote)即可.
AC代码:
1 | |
M:49. 字母异位词分组
题意描述:
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
2输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]示例 2:
2输入: strs = [""]
输出: [[""]]示例 3:
2输入: strs = ["a"]
输出: [["a"]]提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
思路:
两个字符串互为字母异位词,当且仅当两个字符串包含的字母相同。同一组字母异位词中的字符串具备相同点,可以使用相同点作为一组字母异位词的标志,使用哈希表存储每一组字母异位词,哈希表的键为一组字母异位词的标志,哈希表的值为一组字母异位词列表。
遍历每个字符串,对于每个字符串,得到该字符串所在的一组字母异位词的标志,将当前字符串加入该组字母异位词的列表中。遍历全部字符串之后,哈希表中的每个键值对即为一组字母异位词。
以下的两种方法分别使用排序和计数作为哈希表的键。
方法一:排序(本题优选)
由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
emplace关键字是 C++11 的一个新特性。emplace_back()和push_abck()的区别是:push_back()在向 vector 尾部添加一个元素时,首先会创建一个临时对象,然后再将这个临时对象移动或拷贝到 vector 中(如果是拷贝的话,事后会自动销毁先前创建的这个临时元素);而emplace_back()在实现时,则是直接在 vector 尾部创建这个元素,省去了移动或者拷贝元素的过程。
AC代码:
1 | |
时间复杂度:O(nklogk),其中 n 是strs中的字符串的数量,k 是strs中的字符串的的最大长度。需要遍历 n 个字符串,对于每个字符串,需要O(klogk)的时间进行排序以及O(1) 的时间更新哈希表,因此总时间复杂度是O(nklogk)。
空间复杂度:O(nk),其中 n 是strs 中的字符串的数量,k 是 strs 中的字符串的的最大长度。需要用哈希表存储全部字符串。
方法二:计数
由于互为字母异位词的两个字符串包含的字母相同,因此两个字符串中的相同字母出现的次数一定是相同的,故可以将每个字母出现的次数使用字符串表示,作为哈希表的键。
由于字符串只包含小写字母,因此对于每个字符串,可以使用长度为 26 的数组记录每个字母出现的次数。需要注意的是,在使用数组作为哈希表的键时,不同语言的支持程度不同,因此不同语言的实现方式也不同。
AC代码:
1 | |
M:438. 找到字符串中所有字母异位词
题意描述:
给定两个字符串
s和p,找到s中所有p的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
2
3
4
5输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。示例 2:
2
3
4
5
6输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。提示:
1 <= s.length, p.length <= 3 * 104s和p仅包含小写字母
思路:
根据题目要求,我们需要在字符串
s寻找字符串p的异位词。因为字符串p的异位词的长度一定与字符串p的长度相同,所以我们可以在字符串s中构造一个长度为与字符串p的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量;当窗口中每种字母的数量与字符串p中每种字母的数量相同时,则说明当前窗口为字符串p的异位词。在算法的实现中,我们可以使用数组来存储字符串
p和滑动窗口中每种字母的数量。
AC代码:
1 | |
时间复杂度:O(m+(n−m)×Σ),其中 n 为字符串s 的长度,m 为字符串 p的长度,Σ为所有可能的字符数。我们需要 O(m)来统计字符串p中每种字母的数量;需要O(m) 来初始化滑动窗口;需要判断n−m+1个滑动窗口中每种字母的数量是否与字符串 p 中每种字母的数量相同,每次判断需要O(Σ)。因为 s和 p 仅包含小写字母,所以 Σ=26。
空间复杂度:O(Σ)。用于存储字符串 p 和滑动窗口中每种字母的数量。
优化:
在方法一的基础上,我们不再分别统计滑动窗口和字符串
p中每种字母的数量,而是统计滑动窗口和字符串p中每种字母数量的差;并引入变量differ来记录当前窗口与字符串p中数量不同的字母的个数,并在滑动窗口的过程中维护它。在判断滑动窗口中每种字母的数量与字符串
p中每种字母的数量是否相同时,只需要判断differ是否为零即可。
代码:
1 | |
349. 两个数组的交集
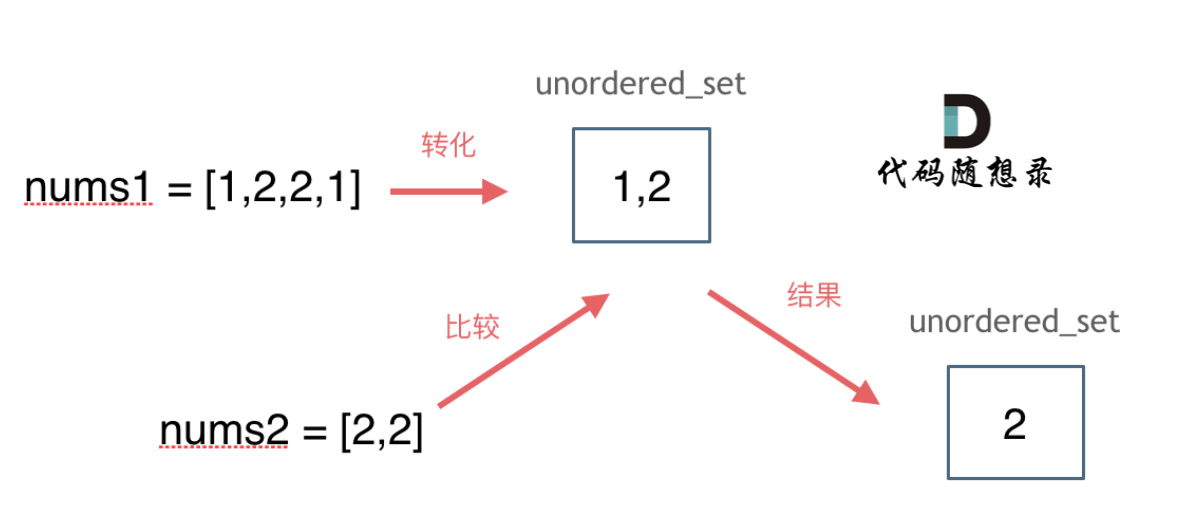
题意描述:
给定两个数组
nums1和nums2,返回它们的交集。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。示例 1:
2输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]示例 2:
2
3输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的提示:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
思路:
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果去重, 同时可以不考虑输出结果的顺序
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
那么用数组来做哈希表也是不错的选择,但是要注意,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了
set,关于set,C++ 给提供了如下三种可用的数据结构:
std::setstd::multisetstd::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
AC代码:
1 | |
- 时间复杂度: O(n + m) ,m 是最后要把 set转成vector
- 空间复杂度: O(n)
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
本题后面力扣改了题目描述 和 后台测试数据,增添了数值范围:
- 1 <= nums1.length, nums2.length <= 1000
- 0 <= nums1[i], nums2[i] <= 1000
所以就可以使用数组来做哈希表, 因为数组都是 1000以内的。
对应C++代码如下:
1 | |
- 时间复杂度: O(m + n)
- 空间复杂度: O(n)
202题. 快乐数
题意描述:
编写一个算法来判断一个数
n是不是快乐数。「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果这个过程 结果为 1,那么这个数就是快乐数。
如果
n是 快乐数 就返回true;不是,则返回false。示例 1:
2
3
4
5
6
7输入:n = 19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1示例 2:
2输入:n = 2
输出:false提示:
1 <= n <= 231 - 1
思路:
这道题目看上去貌似一道数学问题,其实并不是!
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个
sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。判断
sum是否重复出现就可以使用unordered_set。还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。
AC代码:
1 | |
- 时间复杂度: O(logn)
- 空间复杂度: O(logn)