6.10/6.11-字符串
本文最后更新于 2024年10月21日 早上
344.反转字符串
题意描述:
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组
s的形式给出。不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
原地算法(in-place algorithm)是一种使用小的,固定数量的额外之空间来转换资料的算法。即空间复杂度要求o(1)。
示例 1:
2输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]示例 2:
2输入:s = ["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]提示:
1 <= s.length <= 105s[i]都是 ASCII 码表中的可打印字符
思路:
先说一说题外话:
对于这道题目一些同学直接用C++里的一个库函数
reverse,调一下直接完事了, 相信每一门编程语言都有这样的库函数。如果这么做题的话,这样大家不会清楚反转字符串的实现原理了。
但是也不是说库函数就不能用,是要分场景的。
如果在现场面试中,我们什么时候使用库函数,什么时候不要用库函数呢?
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
毕竟面试官一定不是考察你对库函数的熟悉程度, 如果使用
python和java的同学更需要注意这一点,因为python、java提供的库函数十分丰富。如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
建议大家平时在
leetcode上练习算法的时候本着这样的原则去练习,这样才有助于我们对算法的理解。不要沉迷于使用库函数一行代码解决题目之类的技巧,不是说这些技巧不好,而是说这些技巧可以用来娱乐一下。
真正自己写的时候,要保证理解可以实现是相应的功能。
在反转链表中,使用了双指针的方法。
那么反转字符串依然是使用双指针的方法,只不过对于字符串的反转,其实要比链表简单一些。
本题要求原地翻转,因此不能开辟数组。
因为字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
对于字符串,我们定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。
以字符串
hello为例,过程如下:
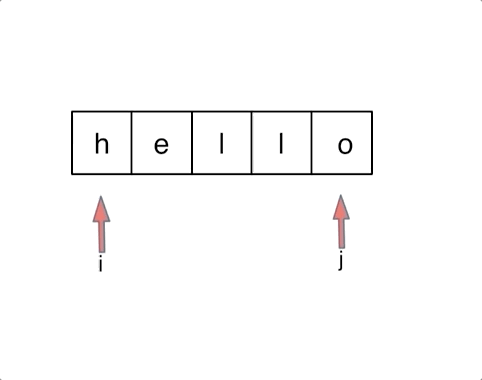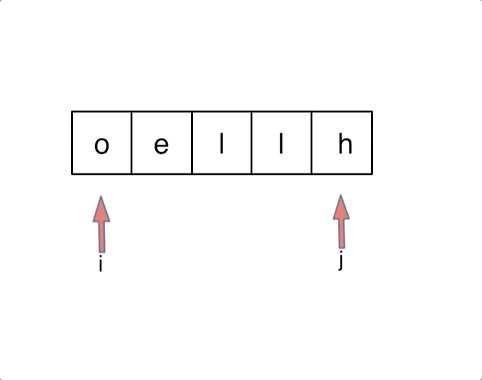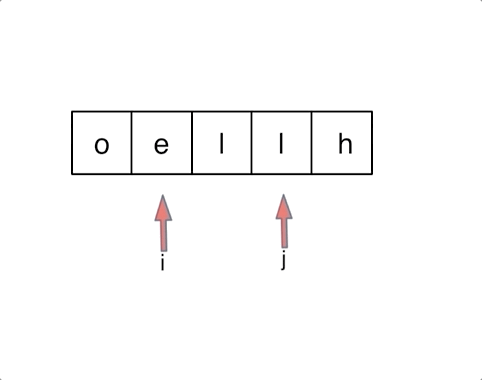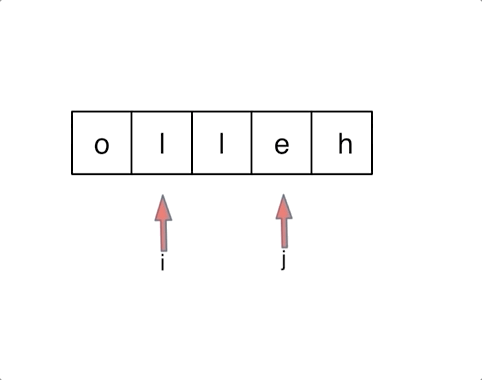
AC代码:
1 | |
循环里只要做交换s[i] 和s[j]操作就可以了,那么我这里使用了swap 这个库函数。大家可以使用。
因为相信大家都知道交换函数如何实现,而且这个库函数仅仅是解题中的一部分, 所以这里使用库函数也是可以的。
swap可以有两种实现。
一种就是常见的交换数值:
1 | |
一种就是通过位运算:
1 | |
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
本着这样的原则,我没有使用reverse库函数,而使用swap库函数。
在字符串相关的题目中,库函数对大家的诱惑力是非常大的,因为会有各种反转,切割取词之类的操作,这也是为什么字符串的库函数这么丰富的原因。
相信大家本着我所讲述的原则来做字符串相关的题目,在选择库函数的角度上会有所原则,也会有所收获。
C++代码如下:
1 | |
- 时间复杂度: O(n)
- 空间复杂度: O(1)
541. 反转字符串II
题意描述:
给定一个字符串
s和一个整数k,从字符串开头算起,每计数至2k个字符,就反转这2k字符中的前k个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。- 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。示例 1
2输入:s = "abcdefg", k = 2
输出:"bacdfeg"示例 2:
2输入:s = "abcd", k = 2
输出:"bacd"提示:
1 <= s.length <= 104s仅由小写英文组成1 <= k <= 104
思路:
这道题目其实也是模拟,实现题目中规定的反转规则就可以了。
一些同学可能为了处理逻辑:每隔2k个字符的前k的字符,写了一堆逻辑代码或者再搞一个计数器,来统计2k,再统计前k个字符。
其实在遍历字符串的过程中,只要让
i += (2 * k),i每次移动2 * k就可以了,然后判断是否需要有反转的区间。因为要找的也就是每
2 * k区间的起点,这样写,程序会高效很多。所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
那么这里具体反转的逻辑我们要不要使用库函数呢,其实用不用都可以,使用
reverse来实现反转也没毛病,毕竟不是解题关键部分。
AC代码:
1 | |
自己实现reverse函数(左闭右开,即相当于start ~ end - 1),库函数reverse是左闭右开的:
1 | |
另解:
1 | |
替换数字(第八期模拟笔试)
题意描述:
给定一个字符串
s,它包含小写字母和数字字符,请编写一个函数,将字符串中的字母字符保持不变,而将每个数字字符替换为number。 例如,对于输入字符串"a1b2c3",函数应该将其转换为"anumberbnumbercnumber"。输入描述
输入一个字符串
s,s仅包含小写字母和数字字符。输出描述
打印一个新的字符串,其中每个数字字符都被替换为了
number输入示例
a1b2c3输出示例
anumberbnumbercnumber提示信息
数据范围:
1 <= s.length < 10000。
思路:
如果想把这道题目做到极致,就不要只用额外的辅助空间了! (不过使用Java刷题的录友,一定要使用辅助空间,因为Java里的string不能修改)
首先扩充数组到每个数字字符替换成 “number” 之后的大小。
例如 字符串 “a5b” 的长度为3,那么 将 数字字符变成字符串 “number” 之后的字符串为 “anumberb” 长度为 8。
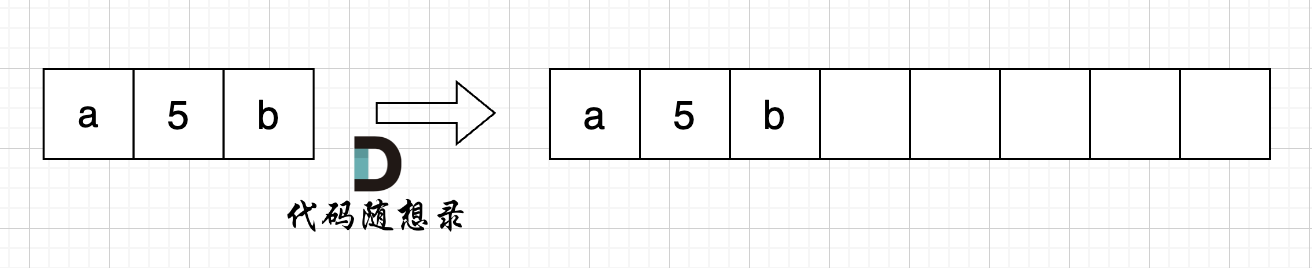
如图:
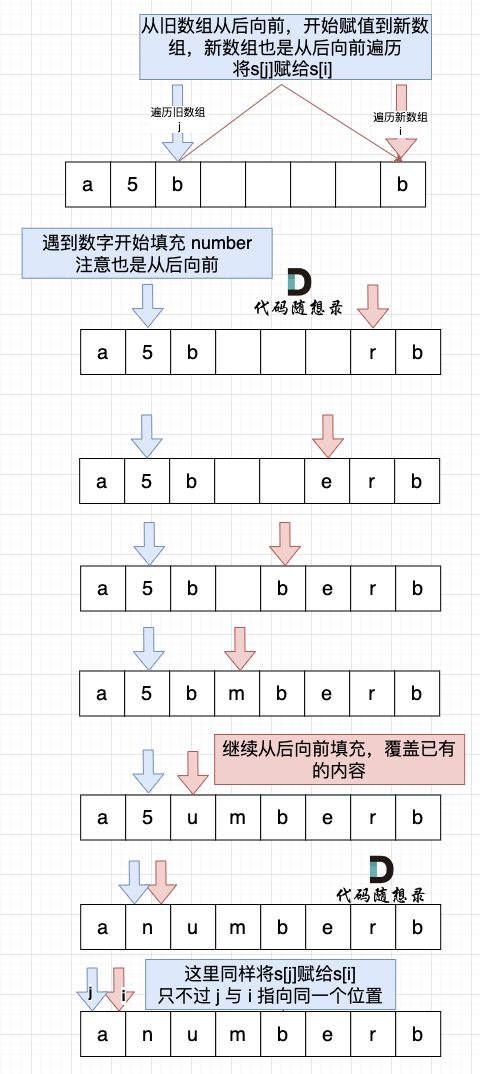
然后从后向前替换数字字符,也就是双指针法,过程如下:i指向新长度的末尾,j指向旧长度的末尾。
有同学问了,为什么要从后向前填充,从前向后填充不行么?
从前向后填充就是
O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素整体向后移动。其实很多数组填充类的问题,其做法都是先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
这么做有两个好处:
- 不用申请新数组。
- 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
AC代码:
1 | |
- 时间复杂度:O(n)
- 空间复杂度:O(1)
拓展:
这里也给大家拓展一下字符串和数组有什么差别,
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,在C语言中,把一个字符串存入一个数组时,也把结束符
'\0'存入数组,并以此作为该字符串是否结束的标志。例如这段代码:
2
3char a[5] = "asd";
for (int i = 0; a[i] != '\0'; i++) {
}在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用’\0’来判断是否结束。
例如这段代码:
2
3string a = "asd";
for (int i = 0; i < a.size(); i++) {
}那么
vector< char >和string又有什么区别呢?其实在基本操作上没有区别,但是
string提供更多的字符串处理的相关接口,例如string重载了+,而vector却没有。所以想处理字符串,我们还是会定义一个
string类型。
M:151.翻转字符串里的单词
题意描述:
给你一个字符串
s,请你反转字符串中 单词 的顺序。单词 是由非空格字符组成的字符串。
s中使用至少一个空格将字符串中的 单词 分隔开。返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串
s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。示例 1:
2输入:s = "the sky is blue"
输出:"blue is sky the"示例 2:
2
3输入:s = " hello world "
输出:"world hello"
解释:反转后的字符串中不能存在前导空格和尾随空格。示例 3:
2
3输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。提示:
1 <= s.length <= 104s包含英文大小写字母、数字和空格' 's中 至少存在一个 单词
思路:
这道题目可以说是综合考察了字符串的多种操作。
一些同学会使用
split库函数,分隔单词,然后定义一个新的string字符串,最后再把单词倒序相加,那么这道题题目就是一道水题了,失去了它的意义。所以这里我还是提高一下本题的难度:不要使用辅助空间,空间复杂度要求为O(1)。
不能使用辅助空间之后,那么只能在原字符串上下功夫了。
想一下,我们将整个字符串都反转过来,那么单词的顺序指定是倒序了,只不过单词本身也倒序了,那么再把单词反转一下,单词不就正过来了。
所以解题思路如下:
- 移除多余空格
- 将整个字符串反转
- 将每个单词反转
举个例子,源字符串为:”the sky is blue “
- 移除多余空格 : “the sky is blue”
- 字符串反转:”eulb si yks eht”
- 单词反转:”blue is sky the”
这样我们就完成了翻转字符串里的单词。
思路很明确了,我们说一说代码的实现细节,就拿移除多余空格来说,一些同学会上来写如下代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15void removeExtraSpaces(string& s) {
for (int i = s.size() - 1; i > 0; i--) {
if (s[i] == s[i - 1] && s[i] == ' ') {
s.erase(s.begin() + i);
}
}
// 删除字符串最后面的空格
if (s.size() > 0 && s[s.size() - 1] == ' ') {
s.erase(s.begin() + s.size() - 1);
}
// 删除字符串最前面的空格
if (s.size() > 0 && s[0] == ' ') {
s.erase(s.begin());
}
}逻辑很简单,从前向后遍历,遇到空格了就erase。
如果不仔细琢磨一下erase的时间复杂度,还以为以上的代码是O(n)的时间复杂度呢。
想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作。
erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
去空格部分代码:
1 | |
如果以上代码看不懂,建议先把 27.移除元素 (opens new window)这道题目做了,或者看视频讲解:数组中移除元素并不容易!LeetCode:27. 移除元素 (opens new window)。
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
还要实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在344.反转字符串 (opens new window)和541.反转字符串II (opens new window)里已经讲过了。
代码如下:
1 | |
整体代码如下:
1 | |
- 时间复杂度: O(n)
- 空间复杂度: O(1) 或 O(n),取决于语言中字符串是否可变
55.右旋字符串(第八期模拟笔试)
题意描述:
字符串的右旋转操作是把字符串尾部的若干个字符转移到字符串的前面。给定一个字符串 s 和一个正整数 k,请编写一个函数,将字符串中的后面 k 个字符移到字符串的前面,实现字符串的右旋转操作。
例如,对于输入字符串
"abcdefg"和整数 2,函数应该将其转换为"fgabcde"。输入:输入共包含两行,第一行为一个正整数 k,代表右旋转的位数。第二行为字符串 s,代表需要旋转的字符串。
输出:输出共一行,为进行了右旋转操作后的字符串。
样例输入:
22
abcdefg样例输出:
fgabcde数据范围:1 <= k < 10000, 1 <= s.length < 10000;
思路:
为了让本题更有意义,提升一下本题难度:不能申请额外空间,只能在本串上操作。 (Java不能在字符串上修改,所以使用java一定要开辟新空间)
不能使用额外空间的话,模拟在本串操作要实现右旋转字符串的功能还是有点困难的。
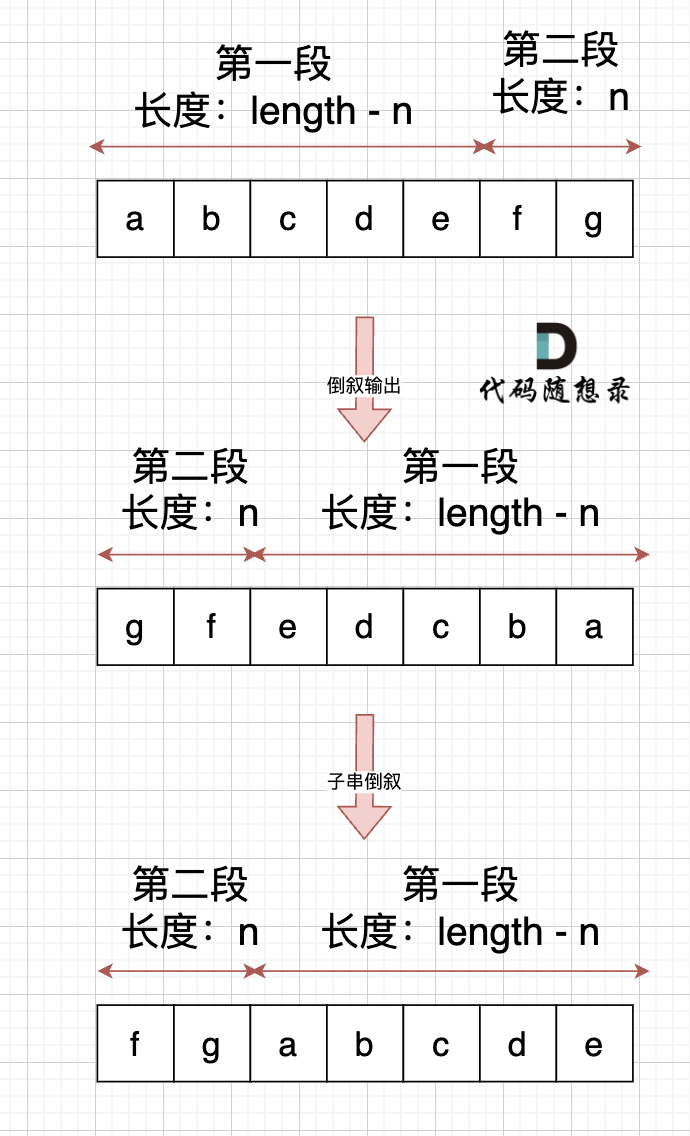
那么我们可以想一下上一题目字符串:花式反转还不够! (opens new window)中讲过,使用整体反转+局部反转就可以实现反转单词顺序的目的。
本题中,我们需要将字符串右移n位,字符串相当于分成了两个部分,如果n为2,符串相当于分成了两个部分,如图: (length为字符串长度)。其实,思路就是 通过 整体倒叙,把两段子串顺序颠倒,两个段子串里的的字符在倒叙一把,负负得正,这样就不影响子串里面字符的顺序了。
AC代码:
1 | |
先局部后整体:
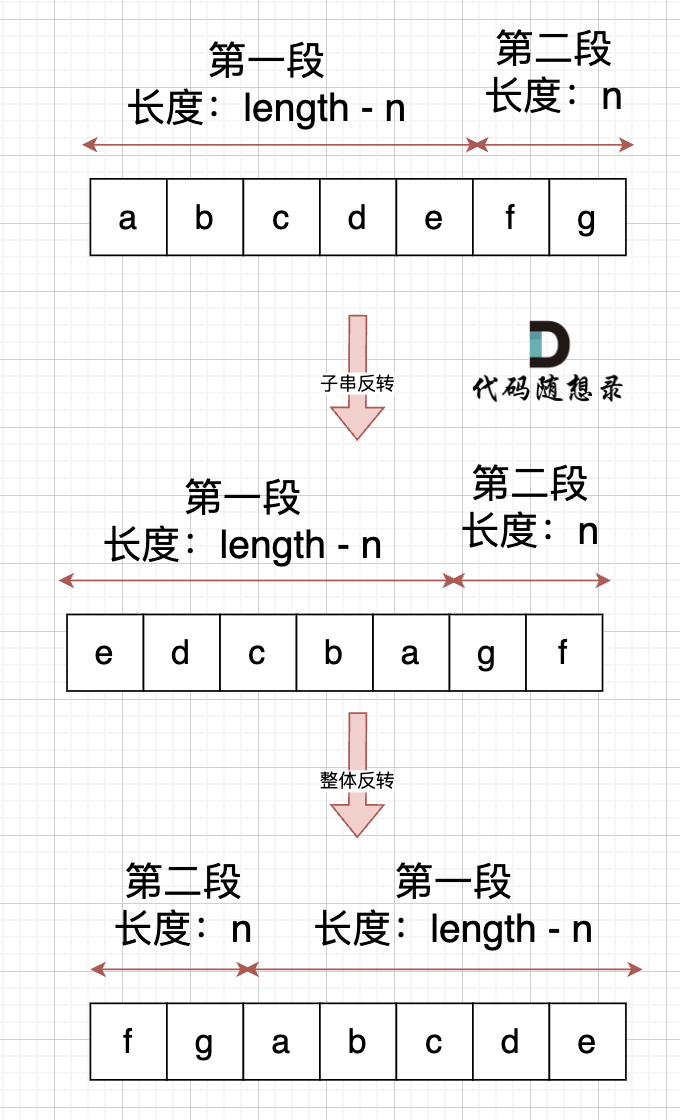
1 | |
KMP算法:28. 实现 strStr()
题意描述:
给你两个字符串
haystack和needle,请你在haystack字符串中找出needle字符串的第一个匹配项的下标(下标从 0 开始)。如果needle不是haystack的一部分,则返回-1示例 1:
2
3
4输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。示例 2:
2
3输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
思路:
前缀表
写过KMP的同学,一定都写过
next数组,那么这个next数组究竟是个啥呢?table)。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
前缀表有什么作用呢?
**前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。**
要在文本串:`aabaabaafa` 中查找是否出现过一个模式串:`aabaaf`。
请记住文本串和模式串的作用,对于理解下文很重要,要不然容易看懵。所以说三遍:
要在文本串:``aabaabaafa`` 中查找是否出现过一个模式串:`aabaaf`。
要在文本串:`aabaabaafa` 中查找是否出现过一个模式串:`aabaaf`。
要在文本串:`aabaabaafa` 中查找是否出现过一个模式串:`aabaaf`。
如动画所示:
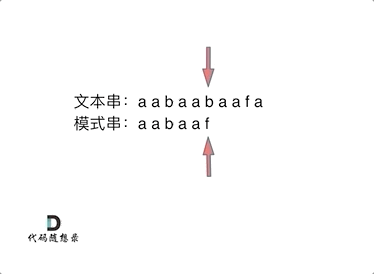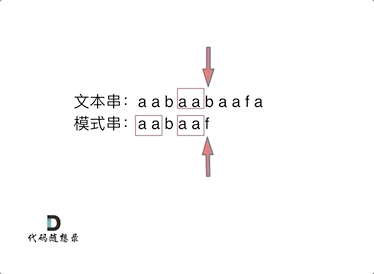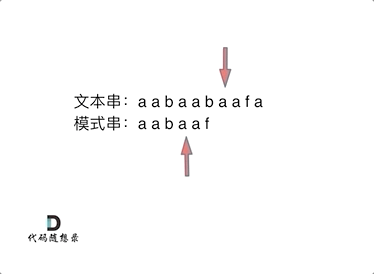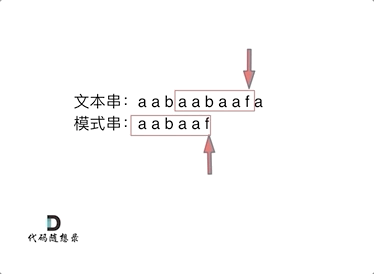
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,发现不匹配,此时就要从头匹配了。
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
那么什么是前缀表:**记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
### 最长公共前后缀
文章中字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**。
**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。
**正确理解什么是前缀什么是后缀很重要**!
那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
我查了一遍 `算法导论 `和 `算法4`里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 更准确一些。
**因为前缀表要求的就是相同前后缀的长度。**
而最长公共前后缀里面的`“公共”`,更像是说前缀和后缀`公共的长度`。这其实并不是前缀表所需要的。
所以字符串a的最长相等前后缀为0。 字符串aa的最长相等前后缀为1。 字符串aaa的最长相等前后缀为2。 等等.....。
### 为什么一定要用前缀表
那为啥就能告诉我们 上次匹配的位置,并跳过去呢?
回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图: 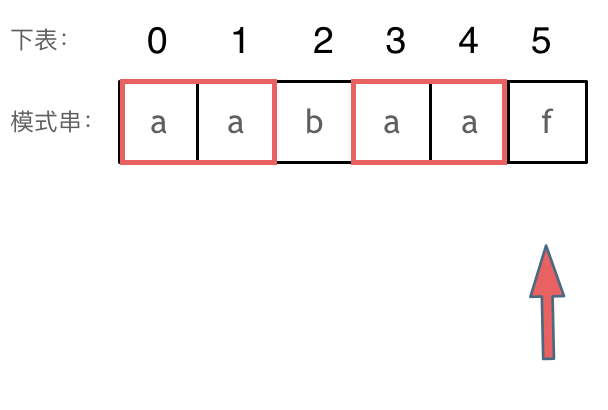
然后就找到了下标2,指向b,继续匹配:如图: 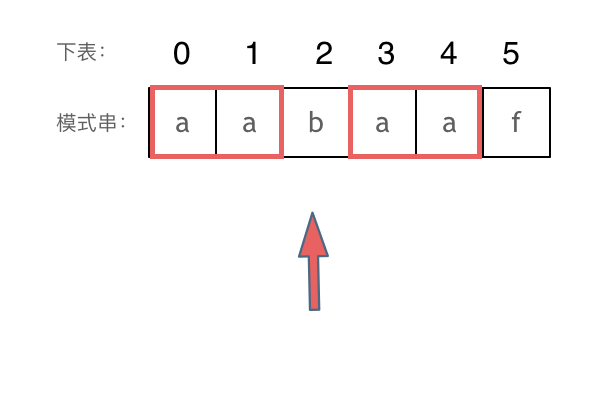
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。**
所以前缀表具有**告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力**。
### 如何计算前缀表
如图:
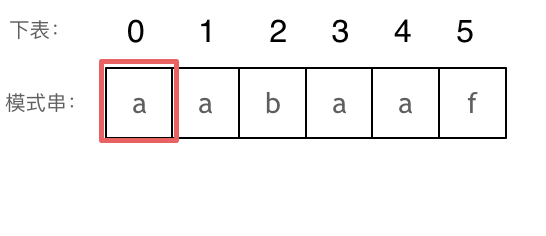
长度为前1个字符的子串`a`,最长相同前后缀的长度为0。(注意字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**;**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。)
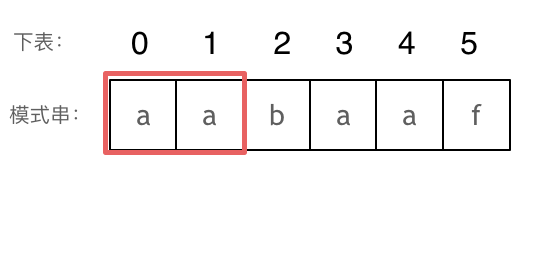
长度为前2个字符的子串`aa`,最长相同前后缀的长度为1。
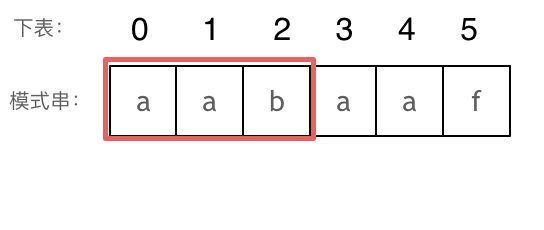
长度为前3个字符的子串`aab`,最长相同前后缀的长度为0。
以此类推: 长度为前4个字符的子串`aaba`,最长相同前后缀的长度为1。 长度为前5个字符的子串`aabaa`,最长相同前后缀的长度为2。 长度为前6个字符的子串`aabaaf`,最长相同前后缀的长度为0。
那么把求得的最长相同前后缀的长度就是对应前缀表的元素,如图: 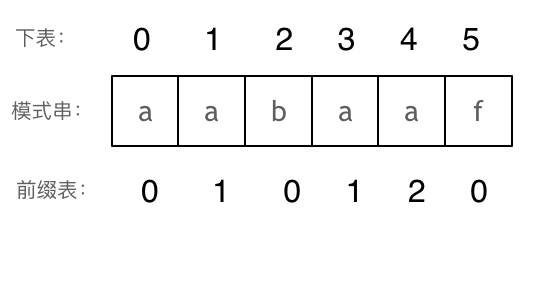
可以看出模式串与前缀表对应位置的数字表示的就是:**下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
再来看一下`如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置`。如动画所示:
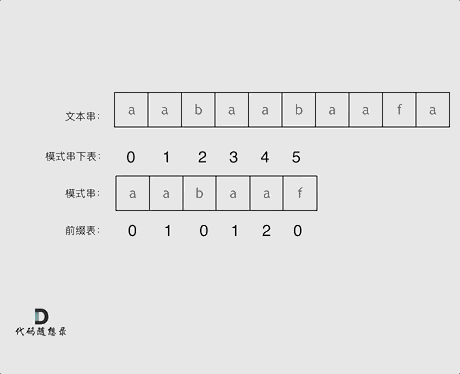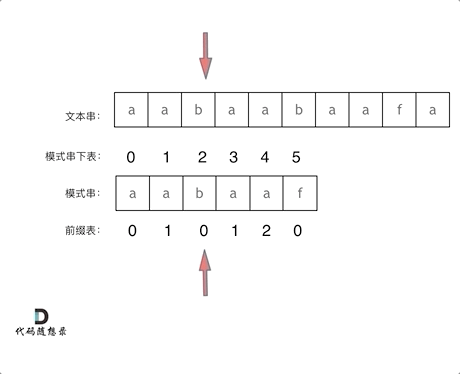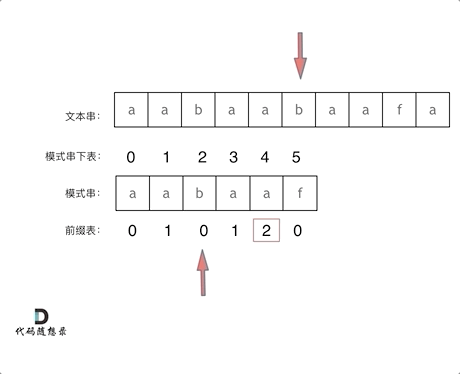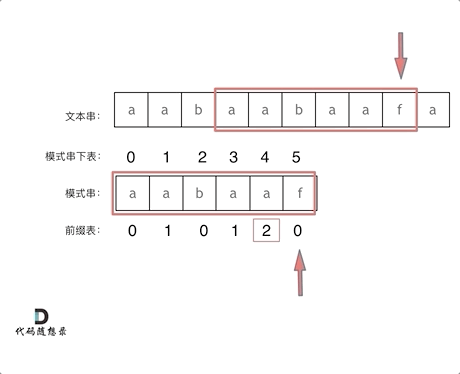
找到的不匹配的位置, 那么此时我们要看它的`前一个字符的前缀表的数值`是多少。
为什么要`前一个字符的前缀表的数值`呢,因为`要找前面字符串的最长相同的前缀和后缀`。
所以要看`前一位的 前缀表的数值`。
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
### 前缀表与``next``数组
很多KMP算法的实现都是使用``next``数组来做回退操作,那么``next``数组与前缀表有什么关系呢?
``next``数组就可以是前缀表,但是很多实现都是**把前缀表统一减一**(右移一位,初始位置为-1)之后作为``next``数组。
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
其实**这并不涉及到KMP的原理,而是具体实现,``next``数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
后面我会提供两种不同的实现代码,大家就明白了。
### 使用`next`数组来匹配
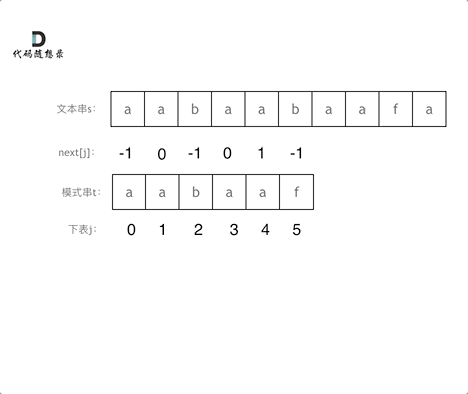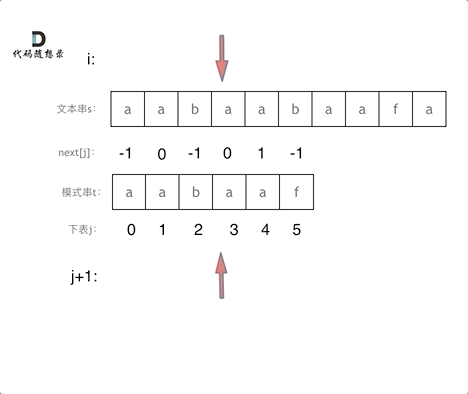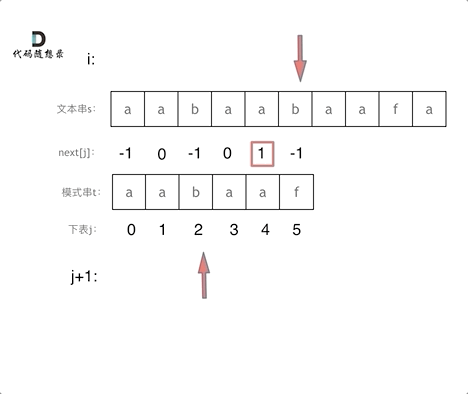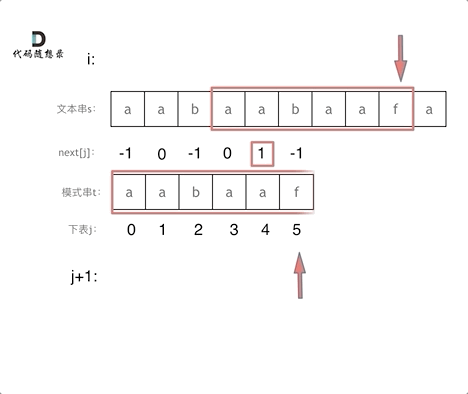
**以下我们以前缀表统一减一之后的`next`数组来做演示**。
有了`next`数组,就可以根据`next`数组来 匹配文本串`s`,和模式串`t`了。
注意`next`数组是新前缀表(旧前缀表统一减一了)。
匹配过程动画如下:
### 时间复杂度分析
其中`n`为文本串长度,`m`为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是`O(n)`,之前还要单独生成`next`数组,时间复杂度是`O(m)`。所以整个KMP算法的时间复杂度是`O(n+m)`的。
暴力的解法显而易见是`O(n × m)`,所以**KMP在字符串匹配中极大地提高了搜索的效率。**
为了和力扣题目`28.实现strStr`保持一致,方便大家理解,以下文章统称`haystack`为文本串, `needle`为模式串。
都知道使用`KMP`算法,一定要构造`next`数组。
### 构造`next`数组
我们定义一个函数`getNext`来构建`next`数组,函数参数为指向`next`数组的指针,和一个字符串。 代码如下:
```cpp
void getNext(int* next, const string& s)构造
next数组其实就是计算模式串s的前缀表的过程。 主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
接下来我们详解一下。
- 初始化:
定义两个指针
i和j,j指向前缀末尾位置,i指向后缀末尾位置。然后还要对
next数组进行初始化赋值,如下:
2int j = -1;
next[0] = j;
j为什么要初始化为-1呢,因为之前说过 前缀表要统一减一的操作仅仅是其中的一种实现,我们这里选择j初始化为-1,下文我还会给出j不初始化为-1的实现代码。
next[i]表示i(包括i)之前最长相等的前后缀长度(其实就是j)所以初始化
next[0] = j。
- 处理前后缀不相同的情况
因为
j初始化为-1,那么i就从1开始,进行s[i]与s[j+1]的比较。所以遍历模式串
s的循环下标i要从1开始,代码如下:
for (int i = 1; i < s.size(); i++) {如果
s[i] s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。怎么回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。那么
s[i]与s[j+1]不相同,就要找j+1前一个元素在next数组里的值(就是next[j])。所以,处理前后缀不相同的情况代码如下:
2
3while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
- 处理前后缀相同的情况
如果
s[i]与s[j + 1]相同,那么就同时向后移动i和j说明找到了相同的前后缀,同时还要将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度。代码如下:
2
3
4if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j;最后整体构建
next数组的函数代码如下:
2
3
4
5
6
7
8
9
10
11
12
13void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}代码构造
next数组的逻辑流程动画如下:
得到了
next数组之后,就要用这个来做匹配了。使用next数组来做匹配
在文本串
s里 找是否出现过模式串t。定义两个下标:
j指向模式串起始位置,i指向文本串起始位置。那么
j初始值依然为-1,为什么呢? 依然因为next数组里记录的起始位置为-1。
i就从0开始,遍历文本串,代码如下:
for (int i = 0; i < s.size(); i++)接下来就是
s[i]与t[j + 1](因为j从-1开始的) 进行比较。如果
s[i]与t[j + 1]不相同,j就要从next数组里寻找下一个匹配的位置。代码如下:
2
3while(j >= 0 && s[i] != t[j + 1]) {
j = next[j];
}如果
s[i]与t[j + 1]相同,那么i和j同时向后移动, 代码如下:
2
3if (s[i] == t[j + 1]) {
j++; // i的增加在for循环里
}如何判断在文本串
s里出现了模式串t呢,如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了。本题要在文本串字符串中找出模式串出现的第一个位置 (从0开始),所以返回当前在文本串匹配模式串的位置
i减去 模式串的长度,就是文本串字符串中出现模式串的第一个位置。代码如下:
2
3if (j == (t.size() - 1) ) {
return (i - t.size() + 1);
}那么使用
next数组,用模式串匹配文本串的整体代码如下:
2
3
4
5
6
7
8
9
10
11
12int j = -1; // 因为next数组里记录的起始位置为-1
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (s[i] == t[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (t.size() - 1) ) { // 文本串s里出现了模式串t
return (i - t.size() + 1);
}
}此时所有逻辑的代码都已经写出来了,
力扣28.实现strStr`题目的整体代码如下:前缀表统一减一
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Solution {
public:
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
vector<int> next(needle.size());
getNext(&next[0], needle);
int j = -1; // // 因为next数组里记录的起始位置为-1
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
return (i - needle.size() + 1);
}
}
return -1;
}
};
- 时间复杂度: O(n + m)
- 空间复杂度: O(m), 只需要保存字符串
needle的前缀表前缀表(不减一)C++实现
那么前缀表就不减一了,也不右移的,到底行不行呢?
我之前说过,这仅仅是
KMP算法实现上的问题,如果就直接使用前缀表可以换一种回退方式,找j=next[j-1]来进行回退。主要就是
j=next[x]这一步最为关键!我给出的
getNext的实现为:(前缀表统一减一)
2
3
4
5
6
7
8
9
10
11
12
13void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}此时如果输入的模式串为
aabaaf,对应的next为-1 0 -1 0 1 -1。这里j和
next[0]初始化为-1,整个next数组是以前缀表减一之后的效果来构建的。那么前缀表不减一来构建
next数组,代码如下:
2
3
4
5
6
7
8
9
10
11
12
13void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}此时如果输入的模式串为
aabaaf,对应的next为0 1 0 1 2 0,(其实这就是前缀表的数值了)。那么用这样的
next数组也可以用来做匹配,代码要有所改动。
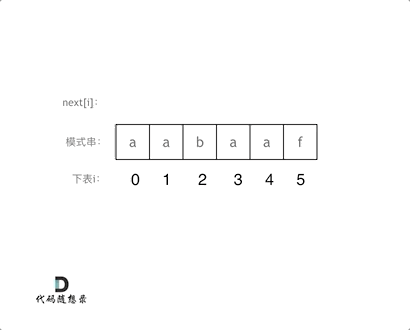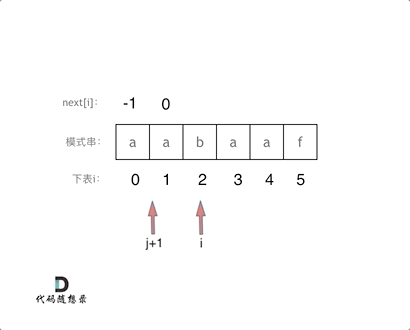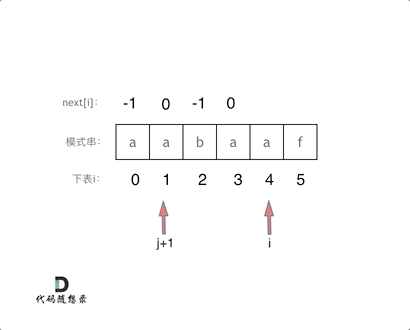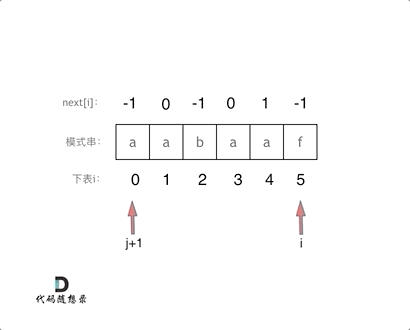
AC代码:
1 | |
- 时间复杂度: O(n + m)
- 空间复杂度: O(m)
459.重复的子字符串
题意描述:
给定一个非空的字符串
s,检查是否可以通过由它的一个子串重复多次构成。示例 1:
2
3输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。示例 2:
2输入: s = "aba"
输出: false示例 3:
2
3输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)提示:
1 <= s.length <= 104s由小写英文字母组成
思路:
暴力的解法, 就是一个for循环获取 子串的终止位置, 然后判断子串是否能重复构成字符串,又嵌套一个for循环,所以是O(n^2)的时间复杂度。
有的同学可以想,怎么一个for循环就可以获取子串吗? 至少得一个for获取子串起始位置,一个for获取子串结束位置吧。
其实我们只需要判断,以第一个字母为开始的子串就可以,所以一个for循环获取子串的终止位置就行了。 而且遍历的时候 都不用遍历结束,只需要遍历到中间位置,因为子串结束位置大于中间位置的话,一定不能重复组成字符串。
暴力的解法,这里就不详细讲解了。
主要讲一讲移动匹配 和 KMP两种方法。
移动匹配
当一个字符串
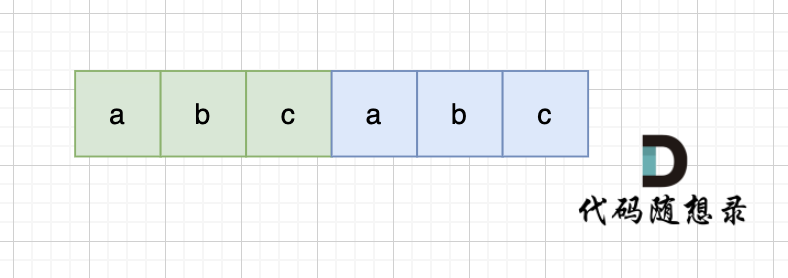
s:abcabc,内部由重复的子串组成,那么这个字符串的结构一定是这样的:
也就是由前后相同的子串组成。
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s,如图:
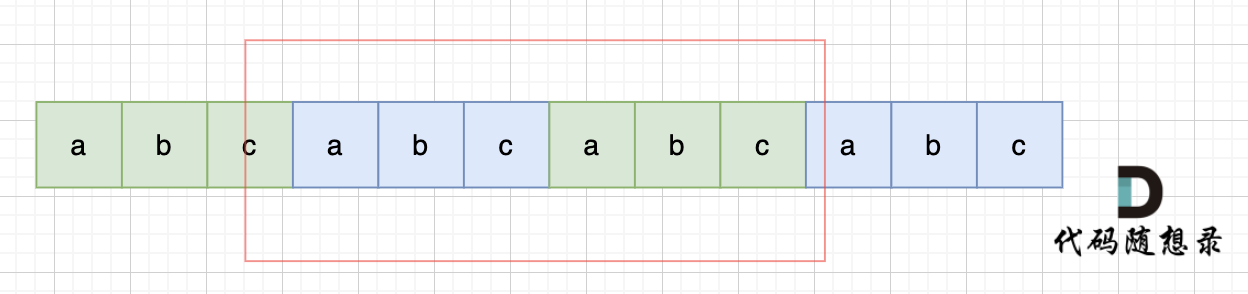
所以判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
AC代码:
1 | |
- 时间复杂度: O(n)
- 空间复杂度: O(1)
不过这种解法还有一个问题,就是 我们最终还是要判断 一个字符串s + s是否出现过s 的过程,大家可能直接用contains,find之类的库函数。 却忽略了实现这些函数的时间复杂度(暴力解法是m * n,一般库函数实现为 O(m + n))。
如果我们做过 28.实现strStr (opens new window)题目的话,其实就知道,实现一个 高效的算法来判断 一个字符串中是否出现另一个字符串是很复杂的,这里就涉及到了KMP算法。
KMP
在一个串中查找是否出现过另一个串,这是
KMP的看家本领。那么寻找重复子串怎么也涉及到KMP算法了呢?
KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一个匹配过的位置继续匹配,靠的是有计算好的前缀表。 前缀表里,统计了各个位置为终点字符串的最长相同前后缀的长度。那么 最长相同前后缀和重复子串的关系又有什么关系呢。
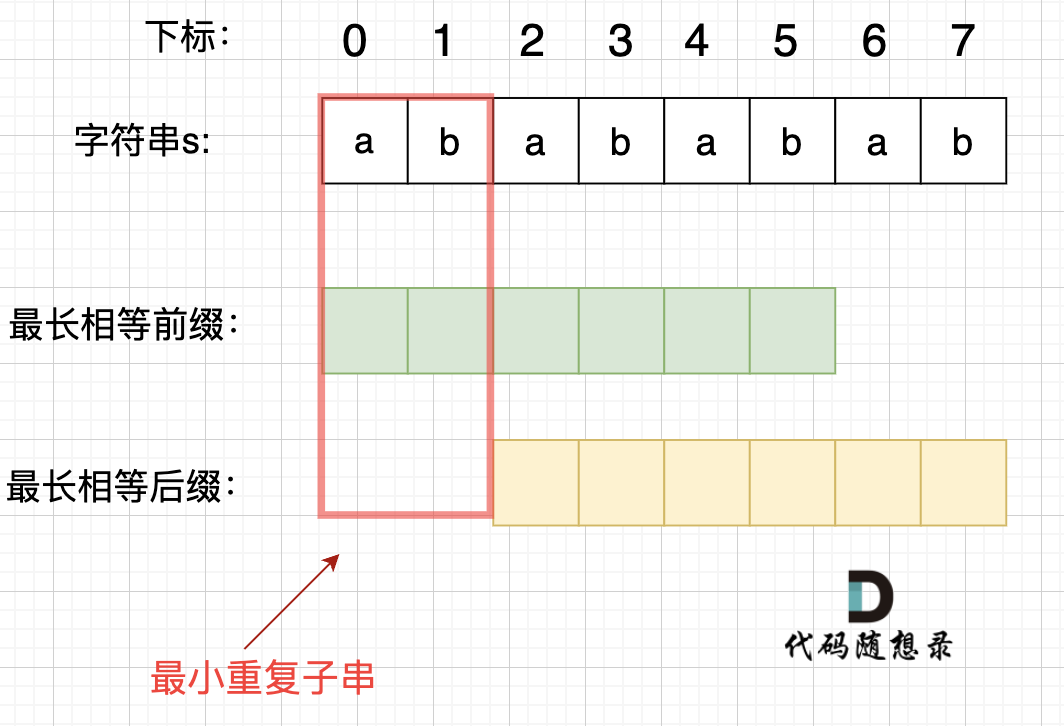
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里拿字符串
s:abababab来举例,ab就是最小重复单位,如图所示:
如何找到最小重复子串
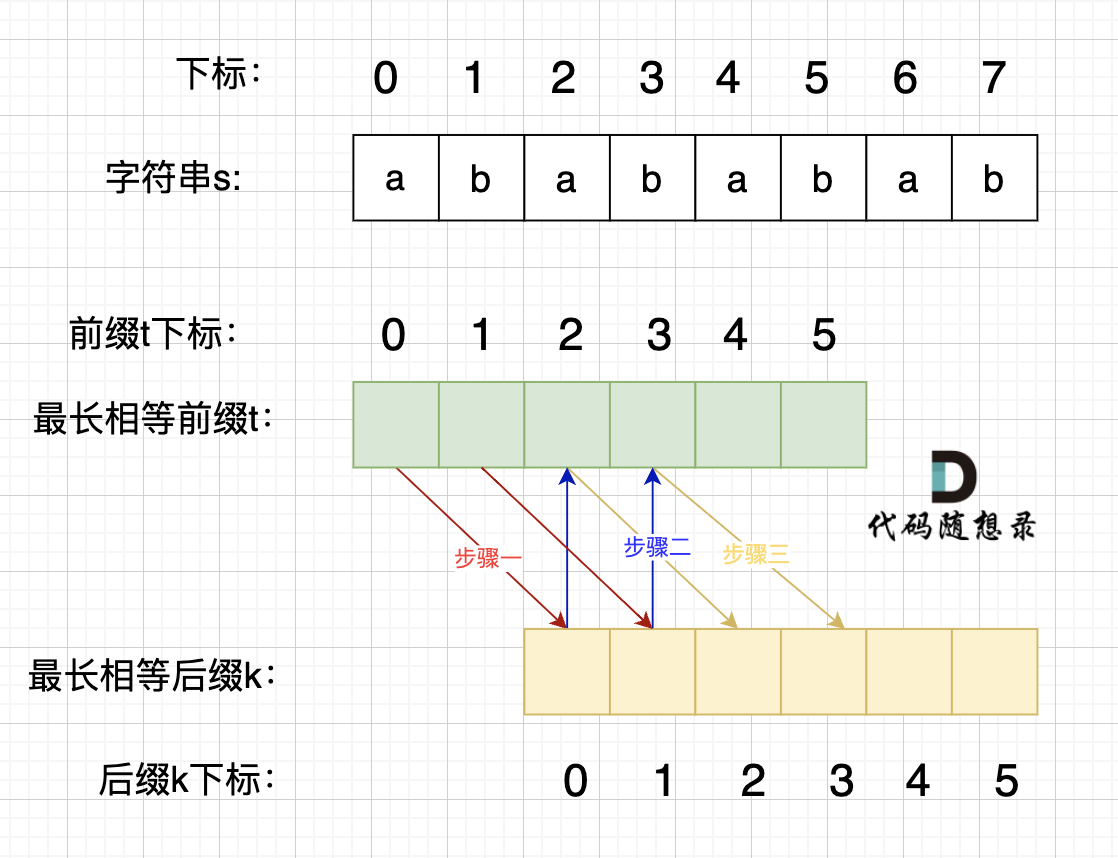
这里有同学就问了,为啥一定是开头的
ab呢。 其实最关键还是要理解最长相等前后缀,如图:
步骤一:因为 这是相等的前缀和后缀,t[0] 与 k[0]相同, t[1] 与 k[1]相同,所以 s[0] 一定和 s[2]相同,s[1] 一定和 s[3]相同,即:,s[0]s[1]与s[2]s[3]相同 。
步骤二: 因为在同一个字符串位置,所以 t[2] 与 k[0]相同,t[3] 与 k[1]相同。
步骤三: 因为 这是相等的前缀和后缀,t[2] 与 k[2]相同 ,t[3]与k[3] 相同,所以,s[2]一定和s[4]相同,s[3]一定和s[5]相同,即:s[2]s[3] 与 s[4]s[5]相同。
步骤四:循环往复。
所以字符串s,s[0]s[1]与s[2]s[3]相同, s[2]s[3] 与 s[4]s[5]相同,s[4]s[5] 与 s[6]s[7] 相同。
正是因为 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。
简单推理
这里再给出一个数学推导,就容易理解很多。
假设字符串
s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。因为字符串
s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且n - m = 1,(这里如果不懂,看上面的推理)所以如果
nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
next数组记录的就是最长相同前后缀 字符串:KMP算法精讲 (opens new window)这里介绍了什么是前缀,什么是后缀,什么又是最长相同前后缀), 如果next[len - 1] != -1,则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度)。最长相等前后缀的长度为:
next[len - 1] + 1。(这里的next数组是以统一减一的方式计算的,因此需要+1,两种计算next数组的具体区别看这里:字符串:KMP算法精讲 (opens new window))数组长度为:
len。如果
len % (len - (next[len - 1] + 1)) == 0,则说明数组的长度正好可以被 (数组长度-最长相等前后缀的长度) 整除 ,说明该字符串有重复的子字符串。数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
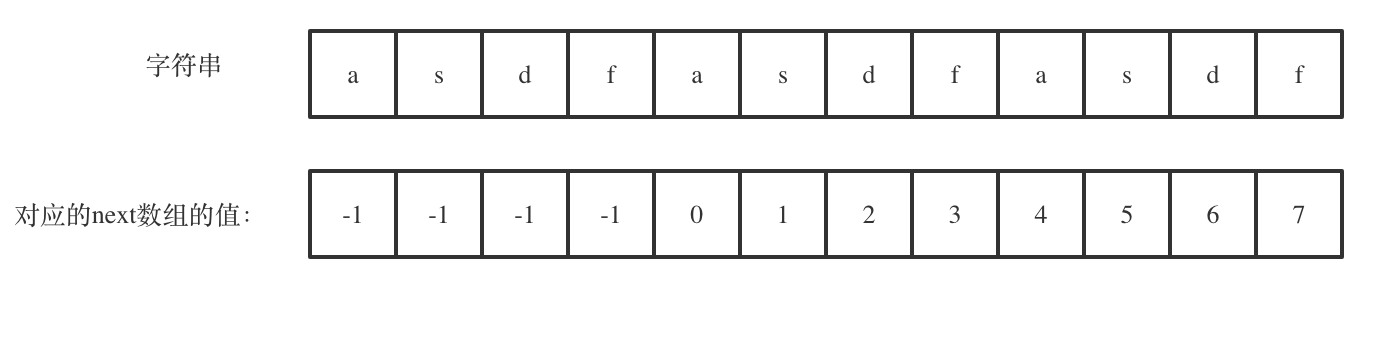
强烈建议大家把next数组打印出来,看看next数组里的规律,有助于理解KMP算法
如图:
next[len - 1] = 7,next[len - 1] + 1 = 8,8就是此时字符串asdfasdfasdf的最长相同前后缀的长度。
(len - (next[len - 1] + 1))也就是:12(字符串的长度) - 8(最长公共前后缀的长度) = 4, 4正好可以被 12(字符串的长度) 整除,所以说明有重复的子字符串(asdf)。
C++代码如下:(这里使用了前缀表统一减一的实现方式)
1 | |
- 时间复杂度: O(n)
- 空间复杂度: O(n)
前缀表(不减一)的C++代码实现:
1 | |
- 时间复杂度: O(n)
- 空间复杂度: O(n)